1、环境
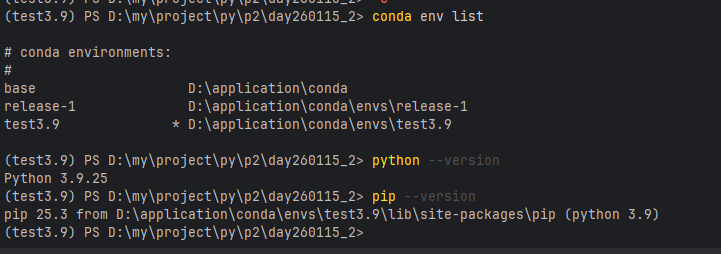
1.1 python环境
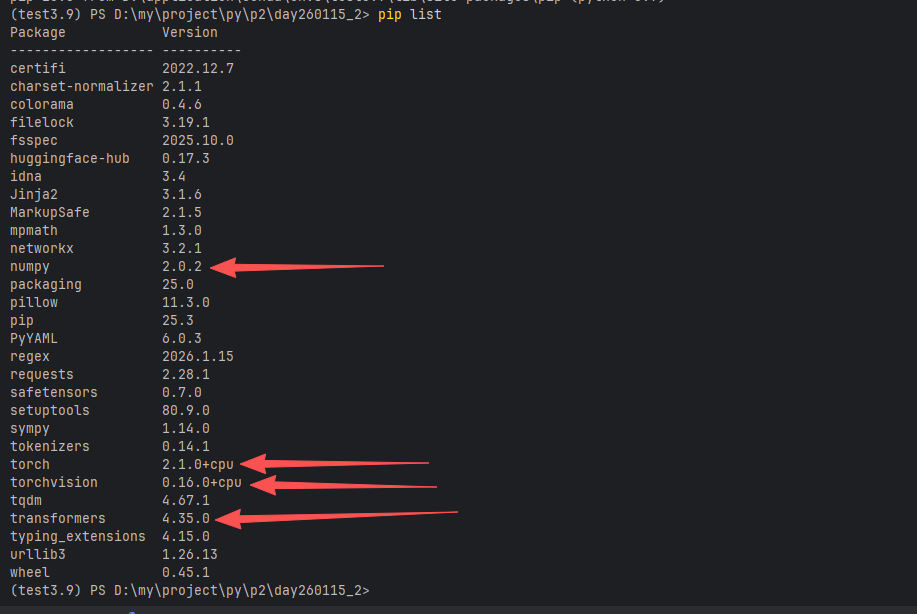
pip install torch==2.1.0 torchvision==0.16.0 --index-url https://download.pytorch.org/whl/cpu
pip install transformers==4.35.01.2 其他环境
1.2.1 中文分词器
无法从 huggingface.co 下载模型和分词器。由于国内访问 huggingface 可能不稳定
1、使用镜像站点(推荐)
将 huggingface.co 替换为镜像地址,例如:https://hf-mirror.com
2、提前下载模型到本地,然后从本地加载
https://hf-mirror.com/bert-base-chinese
已经上传阿里云盘
主要涉及文件
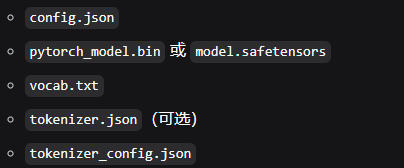
2、代码
2.1 训练代码
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer, BertModel
from torch.optim import AdamW
import os
from sklearn.model_selection import train_test_split
# 设置使用国内镜像(避免下载失败)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
MODEL_PATH = "D:/my/project/py/p2/day260115_2/config/bert-base-chinese" # 修改为你的本地模型路径
print("开始问答模型训练...")
print("=" * 60)
# 1. 准备数据
data = [
{'question': '张三是哪里人', 'answer': '张三是江西人'},
{'question': '张三今年几岁', 'answer': '张三今年30岁'},
{'question': '张三爸妈叫什么名字', 'answer': '张三爸妈名称是张二和王翠花'},
{'question': '张三是哪里的人', 'answer': '张三是江西人'},
{'question': '张三年龄多大', 'answer': '张三今年30岁'},
{'question': '张三父母是谁', 'answer': '张三爸妈名称是张二和王翠花'},
{'question': '张三的籍贯', 'answer': '张三是江西人'},
{'question': '张三多少岁', 'answer': '张三今年30岁'},
{'question': '张三父亲母亲名字', 'answer': '张三爸妈名称是张二和王翠花'},
]
# 2. 数据集类
class QADataset(Dataset):
def __init__(self, data, tokenizer, max_length=64):
self.data = data
self.tokenizer = tokenizer
self.max_length = max_length
# 创建答案到标签的映射
self.answers = list(set([item['answer'] for item in data]))
self.answer_to_idx = {ans: i for i, ans in enumerate(self.answers)}
self.idx_to_answer = {i: ans for i, ans in enumerate(self.answers)}
print(f"数据集包含 {len(self.answers)} 个答案类别:")
for i, ans in enumerate(self.answers):
print(f" {i}: {ans}")
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
question = item['question']
answer = item['answer']
# 编码问题
encoding = self.tokenizer(
question,
truncation=True,
padding='max_length',
max_length=self.max_length,
return_tensors='pt'
)
label = self.answer_to_idx[answer]
return {
'input_ids': encoding['input_ids'].squeeze(0),
'attention_mask': encoding['attention_mask'].squeeze(0),
'label': torch.tensor(label, dtype=torch.long)
}
# 3. 模型定义
class QAModel(nn.Module):
def __init__(self, num_classes, model_path=MODEL_PATH):
super().__init__()
self.bert = BertModel.from_pretrained(model_path)
self.dropout = nn.Dropout(0.3)
self.classifier = nn.Linear(768, num_classes) # BERT输出维度是768
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output # [CLS] token的输出
output = self.dropout(pooled_output)
return self.classifier(output)
# 4. 训练函数
def train_model(model, train_loader, val_loader, dataset_info, epochs=20):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
model = model.to(device)
optimizer = AdamW(model.parameters(), lr=2e-5)
criterion = nn.CrossEntropyLoss()
best_acc = 0
best_model_path = './best_qa_model.pth'
for epoch in range(epochs):
# 训练阶段
model.train()
train_loss = 0
train_correct = 0
train_total = 0
for batch in train_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
# 计算准确率
_, predicted = torch.max(outputs, 1)
train_total += labels.size(0)
train_correct += (predicted == labels).sum().item()
# 验证阶段
model.eval()
val_correct = 0
val_total = 0
with torch.no_grad():
for batch in val_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
outputs = model(input_ids, attention_mask)
_, predicted = torch.max(outputs, 1)
val_total += labels.size(0)
val_correct += (predicted == labels).sum().item()
# 计算指标
train_acc = 100 * train_correct / train_total if train_total > 0 else 0
val_acc = 100 * val_correct / val_total if val_total > 0 else 0
avg_loss = train_loss / len(train_loader)
print(f"Epoch {epoch + 1}/{epochs}")
print(f" 训练损失: {avg_loss:.4f}, 训练准确率: {train_acc:.2f}%")
print(f" 验证准确率: {val_acc:.2f}%")
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
save_checkpoint(model, dataset_info, best_model_path)
print(f" 保存最佳模型到 {best_model_path} (准确率: {val_acc:.2f}%)")
print("-" * 50)
print(f"训练完成!最佳验证准确率: {best_acc:.2f}%")
return model
# 5. 保存模型函数
def save_checkpoint(model, dataset_info, path):
"""保存模型检查点"""
checkpoint = {
'model_state_dict': model.state_dict(),
'answer_to_idx': dataset_info['answer_to_idx'],
'idx_to_answer': dataset_info['idx_to_answer'],
'answers': dataset_info['answers'],
'model_config': {
'model_name': 'bert-base-chinese',
'num_classes': len(dataset_info['answers'])
}
}
# 确保目录存在
os.makedirs(os.path.dirname(path) if os.path.dirname(path) else '.', exist_ok=True)
# 保存模型
torch.save(checkpoint, path)
print(f"模型已保存到 {os.path.abspath(path)}")
# 6. 主函数
def main():
print("1. 加载tokenizer...")
try:
# 尝试从本地路径加载tokenizer
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH, local_files_only=True)
print(f"从本地加载tokenizer成功")
except:
print(f"从本地加载tokenizer失败,尝试在线下载...")
# 如果本地没有,尝试在线下载(可能需要设置代理)
try:
# 设置代理(如果需要)
# os.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
# os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
# 使用国内镜像
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
print(f"从镜像下载tokenizer成功")
except Exception as e:
print(f"加载tokenizer失败: {e}")
print("请手动下载模型文件或设置代理")
return
print("\n2. 准备数据集...")
# 划分训练集和验证集
train_data, val_data = train_test_split(data, test_size=0.2, random_state=42)
print(f" 训练集: {len(train_data)} 个样本")
print(f" 验证集: {len(val_data)} 个样本")
# 创建数据集
train_dataset = QADataset(train_data, tokenizer)
val_dataset = QADataset(val_data, tokenizer)
# 确保验证集使用相同的标签映射
val_dataset.answer_to_idx = train_dataset.answer_to_idx
val_dataset.idx_to_answer = train_dataset.idx_to_answer
val_dataset.answers = train_dataset.answers
print(f"\n3. 创建数据加载器...")
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False)
print(f"\n4. 初始化模型...")
num_classes = len(train_dataset.answers)
model = QAModel(num_classes=num_classes)
# 打印模型信息
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f" 总参数: {total_params:,}")
print(f" 可训练参数: {trainable_params:,}")
print(f"\n5. 开始训练...")
dataset_info = {
'answer_to_idx': train_dataset.answer_to_idx,
'idx_to_answer': train_dataset.idx_to_answer,
'answers': train_dataset.answers
}
trained_model = train_model(
model=model,
train_loader=train_loader,
val_loader=val_loader,
dataset_info=dataset_info,
epochs=15
)
print(f"\n6. 训练完成!")
print(f"模型文件保存在: {os.path.abspath('./best_qa_model.pth')}")
# 验证模型文件是否存在
if os.path.exists('./best_qa_model.pth'):
file_size = os.path.getsize('./best_qa_model.pth') / 1024 / 1024
print(f"模型文件大小: {file_size:.2f} MB")
return True
else:
print("模型文件未找到!")
return False
if __name__ == "__main__":
success = main()
if success:
print("\n训练成功完成!")
print("现在可以运行测试代码了。")
else:
print("\n训练失败!")2.2 测试代码
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertModel
import os
# 方法1: 使用本地路径(推荐)
MODEL_PATH = "D:/my/project/py/p2/day260115_2/config/bert-base-chinese" # 修改为你的本地模型路径
# 1. 模型定义(与训练代码相同)
class QAModel(nn.Module):
def __init__(self, num_classes, bert_model_name=MODEL_PATH):
super(QAModel, self).__init__() # 添加这行
# 从本地路径加载BERT模型
self.bert = BertModel.from_pretrained(bert_model_name)
self.dropout = nn.Dropout(0.3)
self.classifier = nn.Linear(768, num_classes)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output
output = self.dropout(pooled_output)
return self.classifier(output)
# 2. 加载模型
def load_model(model_path='best_qa_model.pth'):
print(f"加载模型: {model_path}")
if not os.path.exists(model_path):
print(f"模型文件不存在: {model_path}")
print("当前目录内容:")
for file in os.listdir('./'):
print(f" {file}")
return None
try:
# 加载检查点
checkpoint = torch.load(model_path, map_location='cpu')
# 打印检查点结构,帮助调试
print(f"检查点结构: {list(checkpoint.keys())}")
# 获取BERT模型名称(如果存在)
bert_model_name = checkpoint.get('model_config', {}).get('bert_model_name', MODEL_PATH)
print(f"使用BERT模型: {bert_model_name}")
# 创建模型实例
if 'model_config' in checkpoint and 'num_classes' in checkpoint['model_config']:
num_classes = checkpoint['model_config']['num_classes']
model = QAModel(num_classes=num_classes, bert_model_name=bert_model_name)
else:
# 兼容旧格式
num_classes = len(checkpoint.get('answers', []))
model = QAModel(num_classes=num_classes, bert_model_name=bert_model_name)
# 加载模型权重
if 'model_state_dict' in checkpoint:
model.load_state_dict(checkpoint['model_state_dict'])
elif 'model_state' in checkpoint:
model.load_state_dict(checkpoint['model_state'])
else:
print("检查点中没有模型权重")
return None
model.eval()
# 加载tokenizer
try:
tokenizer = BertTokenizer.from_pretrained(bert_model_name)
except:
print("⚠️ 使用默认tokenizer")
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
# 获取标签映射
answer_to_idx = checkpoint.get('answer_to_idx', {})
idx_to_answer = checkpoint.get('idx_to_answer', {})
answers = checkpoint.get('answers', [])
# 如果没有标签映射,尝试从其他字段获取
if not answer_to_idx:
if 'label_mappings' in checkpoint:
answer_to_idx = checkpoint['label_mappings'].get('label_to_idx', {})
idx_to_answer = checkpoint['label_mappings'].get('idx_to_label', {})
return {
'model': model,
'tokenizer': tokenizer,
'answer_to_idx': answer_to_idx,
'idx_to_answer': idx_to_answer,
'answers': answers
}
except Exception as e:
print(f"加载模型失败: {e}")
import traceback
traceback.print_exc()
return None
# 3. 预测函数
def predict(question, qa_system, top_k=1):
tokenizer = qa_system['tokenizer']
model = qa_system['model']
idx_to_answer = qa_system['idx_to_answer']
# 编码输入
encoding = tokenizer(
question,
truncation=True,
padding='max_length',
max_length=64,
return_tensors='pt'
)
input_ids = encoding['input_ids']
attention_mask = encoding['attention_mask']
# 预测
with torch.no_grad():
outputs = model(input_ids, attention_mask)
probabilities = torch.softmax(outputs, dim=1)
if top_k == 1:
predicted_idx = torch.argmax(probabilities, dim=1).item()
confidence = probabilities[0][predicted_idx].item()
return {
'question': question,
'answer': idx_to_answer.get(predicted_idx, f"未知答案 (索引: {predicted_idx})"),
'confidence': confidence,
'all_answers': [
(idx_to_answer.get(i, f"未知{i}"), prob.item())
for i, prob in enumerate(probabilities[0])
]
}
else:
# 返回top_k个结果
top_probs, top_indices = torch.topk(probabilities, top_k)
results = []
for i in range(top_k):
idx = top_indices[0][i].item()
prob = top_probs[0][i].item()
results.append({
'answer': idx_to_answer.get(idx, f"未知答案 (索引: {idx})"),
'confidence': prob,
'rank': i + 1
})
return {'question': question, 'results': results}
# 4. 测试函数
def test_model():
print("测试问答模型")
print("=" * 50)
# 加载模型
qa_system = load_model()
if qa_system is None:
print("无法加载模型,请检查文件是否存在")
return
print(f"\n模型加载成功!")
# 显示模型信息
if qa_system['answers']:
print(f"支持 {len(qa_system['answers'])} 个答案:")
for idx, answer in qa_system['idx_to_answer'].items():
print(f" {idx}: {answer}")
else:
print("⚠️ 没有找到答案列表")
if qa_system['idx_to_answer']:
print(f"找到 {len(qa_system['idx_to_answer'])} 个答案映射:")
for idx, answer in qa_system['idx_to_answer'].items():
print(f" {idx}: {answer}")
# 测试问题
test_questions = [
"张三是哪里人",
"张三今年几岁",
"张三爸妈叫什么名字",
"张三的籍贯是哪里",
"张三多大年龄",
"张三的父亲母亲是谁"
]
print(f"\n开始测试...")
print("-" * 50)
for question in test_questions:
print(f"\nQ: {question}")
try:
result = predict(question, qa_system)
print(f"A: {result['answer']}")
print(f"置信度: {result['confidence']:.2%}")
# 显示所有可能的答案
print("所有答案的可能性:")
for answer, prob in sorted(result['all_answers'], key=lambda x: x[1], reverse=True):
if prob > 0.01: # 只显示大于1%的
print(f" {answer}: {prob:.2%}")
except Exception as e:
print(f"预测失败: {e}")
# 5. 交互式问答
def interactive_qa():
print("交互式问答系统")
print("输入 'quit' 退出")
print("=" * 50)
# 加载模型
qa_system = load_model()
if qa_system is None:
print("无法加载模型")
return
while True:
try:
question = input("\n请输入问题: ").strip()
if question.lower() in ['quit', 'exit', '退出']:
print("再见!")
break
if not question:
continue
result = predict(question, qa_system)
print(f"\n答案: {result['answer']}")
print(f"置信度: {result['confidence']:.2%}")
# 显示前3个可能的答案
print("其他可能答案:")
for answer, prob in sorted(result['all_answers'], key=lambda x: x[1], reverse=True)[:3]:
if prob > 0.01:
print(f" {answer}: {prob:.2%}")
except KeyboardInterrupt:
print("\n\n再见!")
break
except Exception as e:
print(f"错误: {e}")
# 6. 检查模型文件
def check_model_file():
print("检查模型文件...")
model_path = './best_qa_model.pth'
if not os.path.exists(model_path):
print(f"模型文件不存在: {model_path}")
print("请先运行训练程序")
return
file_size = os.path.getsize(model_path) / 1024 / 1024
print(f"模型文件存在")
print(f"文件大小: {file_size:.2f} MB")
print(f"完整路径: {os.path.abspath(model_path)}")
# 尝试加载模型
try:
checkpoint = torch.load(model_path, map_location='cpu')
print(f"\n可以加载检查点")
print(f"检查点包含的键: {list(checkpoint.keys())}")
# 显示详细信息
for key, value in checkpoint.items():
if isinstance(value, dict):
print(f"{key}: 字典,包含 {len(value)} 个项目")
elif isinstance(value, list):
print(f"{key}: 列表,包含 {len(value)} 个项目")
elif torch.is_tensor(value):
print(f"{key}: 张量,形状: {value.shape}")
else:
print(f"{key}: {type(value)}")
except Exception as e:
print(f"加载检查点失败: {e}")
if __name__ == "__main__":
print("=" * 50)
print("问答模型测试程序")
print("=" * 50)
# 先检查模型文件
check_model_file()
print("\n" + "=" * 50)
# 询问用户选择
choice = input("\n请选择操作: \n1. 测试模型 \n2. 交互式问答 \n3. 退出 \n请输入数字: ").strip()
if choice == '1':
test_model()
elif choice == '2':
interactive_qa()
else:
print("退出程序")2.3 结果