

1、启动docker
docker run -p 10095:10095 -p 5000:5000 -it --privileged=true -v $PWD/funasr-runtime-resources/models:/workspace/models -v $PWD/funasr-runtime-resources/app:/workspace/app --name funasr-voice registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.4.6含义
1、-p 10095:10095:funasr内部模型的ws端口
2、-p 5000:5000:内部自定义应用端口
3、-it:启动成功之后,进入容器内部
4、-v $PWD/funasr-runtime-resources/models:/workspace/models:funasr模型映射路径
5、-v $PWD/funasr-runtime-resources/app:/workspace/app:app自定义应用映射路径
6、--name funasr-voice:容器名称
7、registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.4.6:容器镜像,已上传云盘

1.1 安装环境
进入容器内部之后,安装环境
1、安装python的flask。启动服务
pip install flask2、部署语音大模型
这里使用:modelscope 的 iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn
但是由于这个模型不支持onnx,所以直接通过Funasr的run_server.sh是没办法启动的,下面采用python方式启动
2.1、下载模型
进入容器内部之后,进入路径:/workspace/app
执行下面下载命令,模型已经上传云盘
modelscope download --model iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn --local_dir ./models/iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn
modelscope download --model iic/speech_fsmn_vad_zh-cn-16k-common-pytorch --local_dir ./models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch
modelscope download --model iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch --local_dir ./models/iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch
modelscope download --model iic/speech_campplus_sv_zh-cn_16k-common --local_dir ./models/iic/speech_campplus_sv_zh-cn_16k-common
2.2、创建python服务
2.2.1、在线运行
每次启动python都会在线下载模型,启动之后,使用不会再次下载
在线运行,就不需要执行上面模型下载步骤
touch voice_server.pyfrom flask import Flask, request, jsonify
from funasr import AutoModel
import os
app = Flask(__name__)
# 加载模型(服务启动时加载一次,后续请求复用)
model = AutoModel(
model="iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn",
vad_model="fsmn-vad",
punc_model="ct-punc-c",
spk_model="cam++",
model_revision="v2.0.4"
)
@app.route('/asr', methods=['POST'])
def recognize():
# 接收上传的音频文件
audio_file = request.files['audio']
save_path = f"/tmp/{audio_file.filename}"
audio_file.save(save_path)
# 进行语音识别
result = model.generate(input=save_path)
# 清理临时文件
os.remove(save_path)
# 返回识别结果
return jsonify(result)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)启动即可
python voice_server.py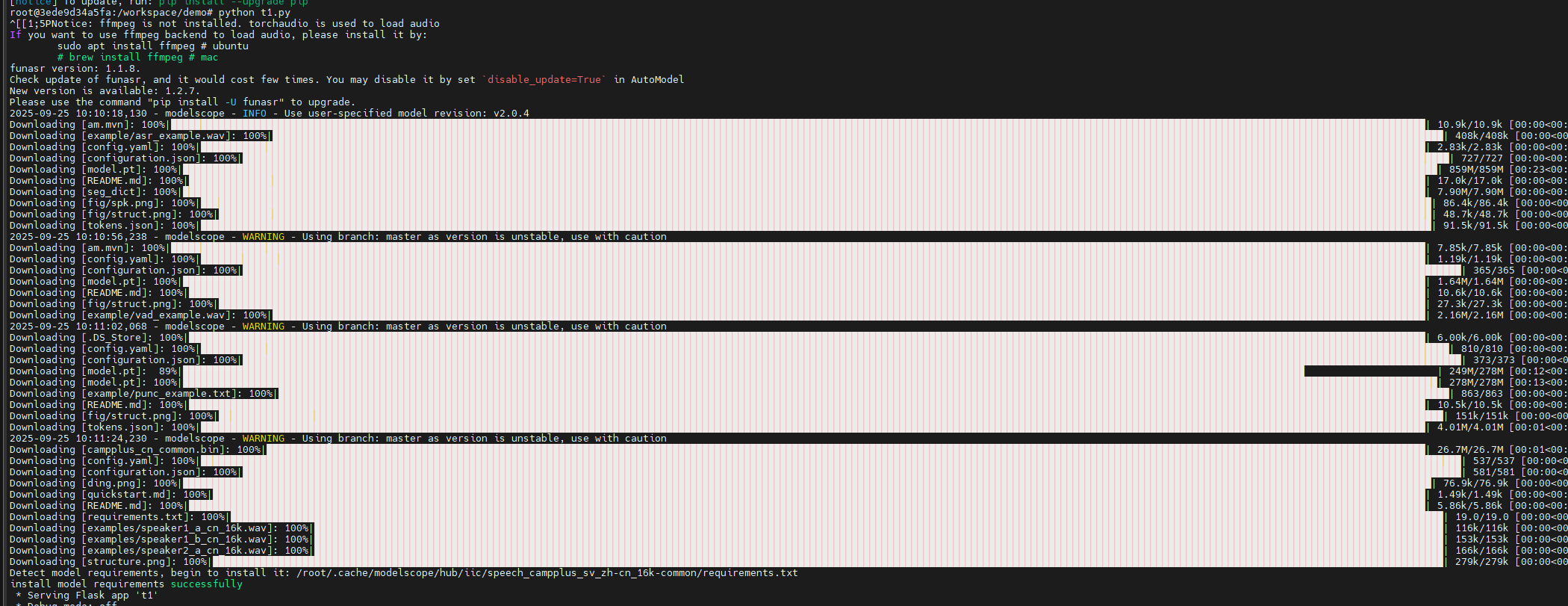
2.2.2、离线运行
执行上面模型下载,然后上传到指定目录
touch voice_server.pyfrom flask import Flask, request, jsonify
from funasr import AutoModel
import os
app = Flask(__name__)
MODEL_DIR = "./models"
model = AutoModel(
model=os.path.join(MODEL_DIR, "iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn"),
vad_model=os.path.join(MODEL_DIR, "iic/speech_fsmn_vad_zh-cn-16k-common-pytorch"),
punc_model=os.path.join(MODEL_DIR, "iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch"),
spk_model=os.path.join(MODEL_DIR, "iic/speech_campplus_sv_zh-cn_16k-common"),
model_revision="v2.0.4",
disable_update=True
)
@app.route('/asr', methods=['POST'])
def recognize():
if 'audio' not in request.files:
return jsonify({"error": "No audio file provided"}), 400
audio_file = request.files['audio']
if audio_file.filename == '':
return jsonify({"error": "No selected file"}), 400
save_path = f"/tmp/{audio_file.filename}"
audio_file.save(save_path)
try:
result = model.generate(input=save_path)
os.remove(save_path)
return jsonify(result)
except Exception as e:
if os.path.exists(save_path):
os.remove(save_path)
return jsonify({"error": str(e)}), 500
@app.route('/health', methods=['GET'])
def health_check():
return jsonify({"status": "healthy", "model_loaded": True})
if __name__ == '__main__':
if not os.path.exists(MODEL_DIR):
os.makedirs(MODEL_DIR)
print(f"warm: model {MODEL_DIR} not find,Created. Please ensure that the model has been downloaded to this directory.")
app.run(host='0.0.0.0', port=5000, debug=False)注意AutoModel创建的时候,4个模型对应的位置即可,启动

2.2.3 基于gunicorn运行
2.2.3.1、环境安装
pip install gunicorn2、安装依赖
创建requirements.txt
内容:
flask>=2.0.0
funasr>=0.8.0
modelscope>=1.9.0
gunicorn>=20.0.0执行命令,安装
pip install -r requirements.txt2.2.3.2、创建gunicorn_config.py
import os
import multiprocessing
bind = "0.0.0.0:5000"
# work thread
workers = multiprocessing.cpu_count() * 2 + 1
# work model
worker_class = "sync"
# Restart after each worker process has processed the number of requests
max_requests = 1000
max_requests_jitter = 100
timeout = 120
# Daemon mode
daemon = False
# log info
accesslog = "./logs/access.log"
errorlog = "./logs/error.log"
loglevel = "info"
# pid info
pidfile = "./tmp/gunicorn.pid"
# Preload the application (Important: Ensure that the model is loaded only once)
preload_app = True
# xecuted before the work process starts
def pre_fork(server, worker):
# Make sure the log directory exists
os.makedirs("./logs", exist_ok=True)
os.makedirs("./tmp", exist_ok=True)
def when_ready(server):
server.log.info("During the server startup, it may take a relatively long time for the model to load...")
# Executed when the work process exits
def worker_exit(server, worker):
# You can add the cleaning code here
pass2.2.3.3、创建start_server.sh
#!/bin/bash
export PYTHONPATH=$PYTHONPATH:$(pwd)
export MODEL_DIR="./models"
# create dir
mkdir -p ./logs
mkdir -p ./tmp
# check dir
if [ ! -d "$MODEL_DIR" ]; then
echo "warm: model dir $MODEL_DIR not find"
echo "Please ensure that the model file has been downloaded"
fi
# start Gunicorn server
echo "Launch the FunASR voice recognition service..."
echo "The server will run on: http://0.0.0.0:5000"
echo "log file: ./logs/access.log and ./logs/error.log"
gunicorn -c gunicorn_config.py app:appchmod +x start_server.sh2.2.3.4、创建app.py
from flask import Flask, request, jsonify
from funasr import AutoModel
import os
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
app = Flask(__name__)
MODEL_DIR = "./models"
os.environ['MODELSCOPE_CACHE'] = './models'
os.environ['MODELSCOPE_HUB_CACHE'] = './models'
model = None
def load_model():
global model
try:
logger.info("Start loading the speech recognition model...")
model = AutoModel(
model=os.path.join(MODEL_DIR, "iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn"),
vad_model=os.path.join(MODEL_DIR, "iic/speech_fsmn_vad_zh-cn-16k-common-pytorch"),
punc_model=os.path.join(MODEL_DIR, "iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch"),
spk_model=os.path.join(MODEL_DIR, "iic/speech_campplus_sv_zh-cn_16k-common"),
model_revision="v2.0.4",
disable_update=True
)
logger.info("The speech recognition model has been successfully loaded")
except Exception as e:
logger.error(f"Model loading failed: {e}")
raise
load_model()
@app.route('/asr', methods=['POST'])
def recognize():
if model is None:
return jsonify({"error": "The model is not loaded."}), 500
if 'audio' not in request.files:
return jsonify({"error": "No audio file was provided"}), 400
audio_file = request.files['audio']
if audio_file.filename == '':
return jsonify({"error": "Unselected file"}), 400
save_path = f"/tmp/{audio_file.filename}"
audio_file.save(save_path)
try:
logger.info(f"Start processing the audio file: {audio_file.filename}")
result = model.generate(input=save_path)
logger.info(f"Audio processing completed: {audio_file.filename}")
os.remove(save_path)
return jsonify({
"success": True,
"result": result
})
except Exception as e:
logger.error(f"An error occurred while processing the audio: {e}")
if os.path.exists(save_path):
os.remove(save_path)
return jsonify({"error": str(e)}), 500
@app.route('/health', methods=['GET'])
def health_check():
status = "healthy" if model is not None else "unhealthy"
return jsonify({
"status": status,
"service": "funasr-asr",
"model_loaded": model is not None
})
@app.route('/', methods=['GET'])
def index():
return jsonify({
"service": "FunASR voice recognition service",
"version": "1.0",
"endpoints": {
"asr": "/asr (POST)",
"health": "/health (GET)"
}
})
if __name__ == '__main__':
load_model()
app.run(host='0.0.0.0', port=5000, debug=False)2.2.3.5、启动
1、直接通过gunicorn_config.py 启动
gunicorn -c gunicorn_config.py app:app2、通过脚本启动
./start_server.sh2.2.3.6 创建系统服务文件(可选)
创建 funasr.service(用于systemd):
[Unit]
Description=FunASR Speech Recognition Service
After=network.target
[Service]
Type=simple
User=www-data
Group=www-data
WorkingDirectory=/path/to/your/app
Environment=PYTHONPATH=/path/to/your/app
Environment=MODEL_DIR=/path/to/your/app/models
ExecStart=/usr/local/bin/gunicorn -c gunicorn_config.py app:app
ExecReload=/bin/kill -s HUP $MAINPID
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target2.3 测试
上面两种方式,访问路径都是:http://192.168.1.111:5000/asr
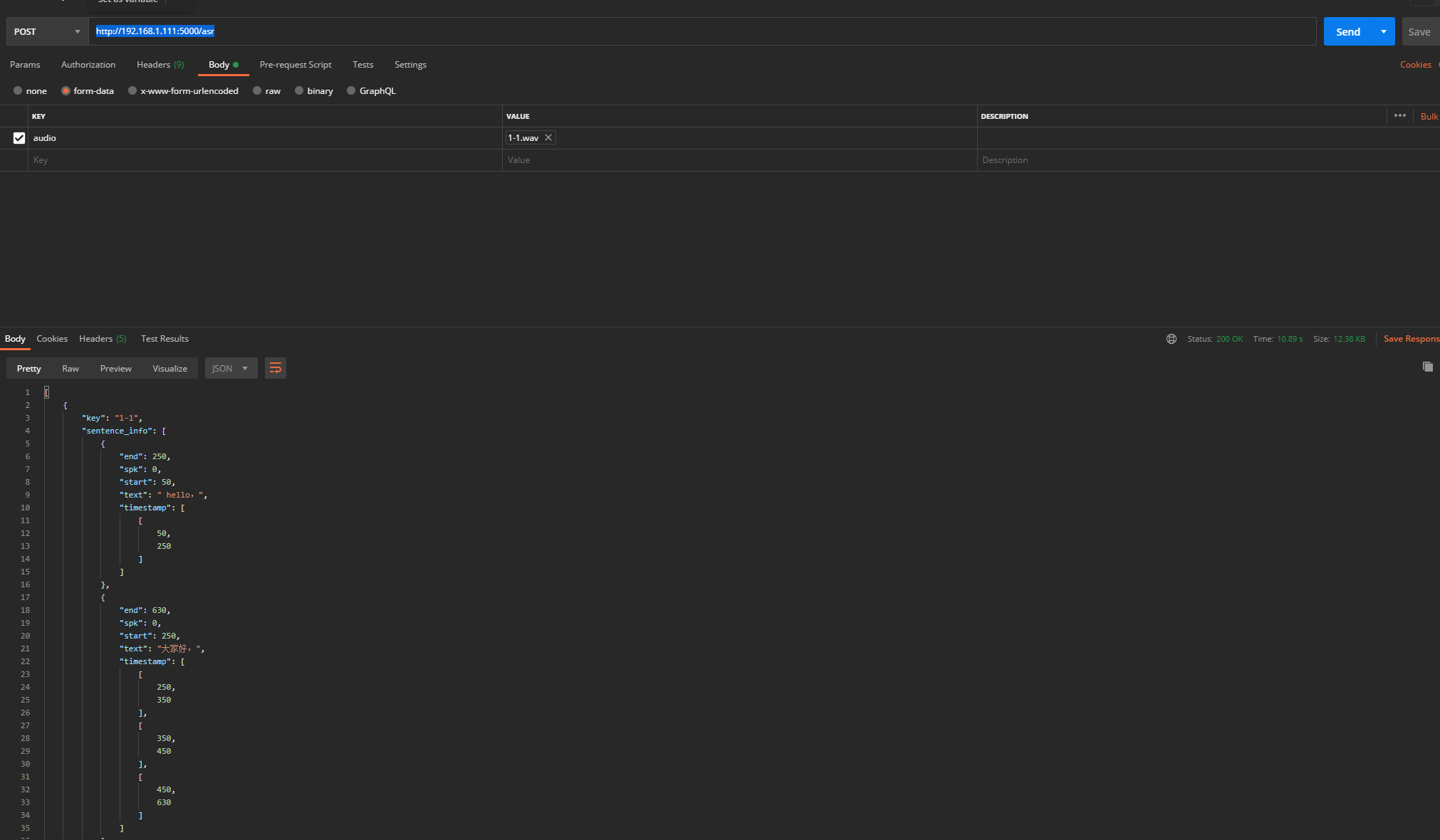
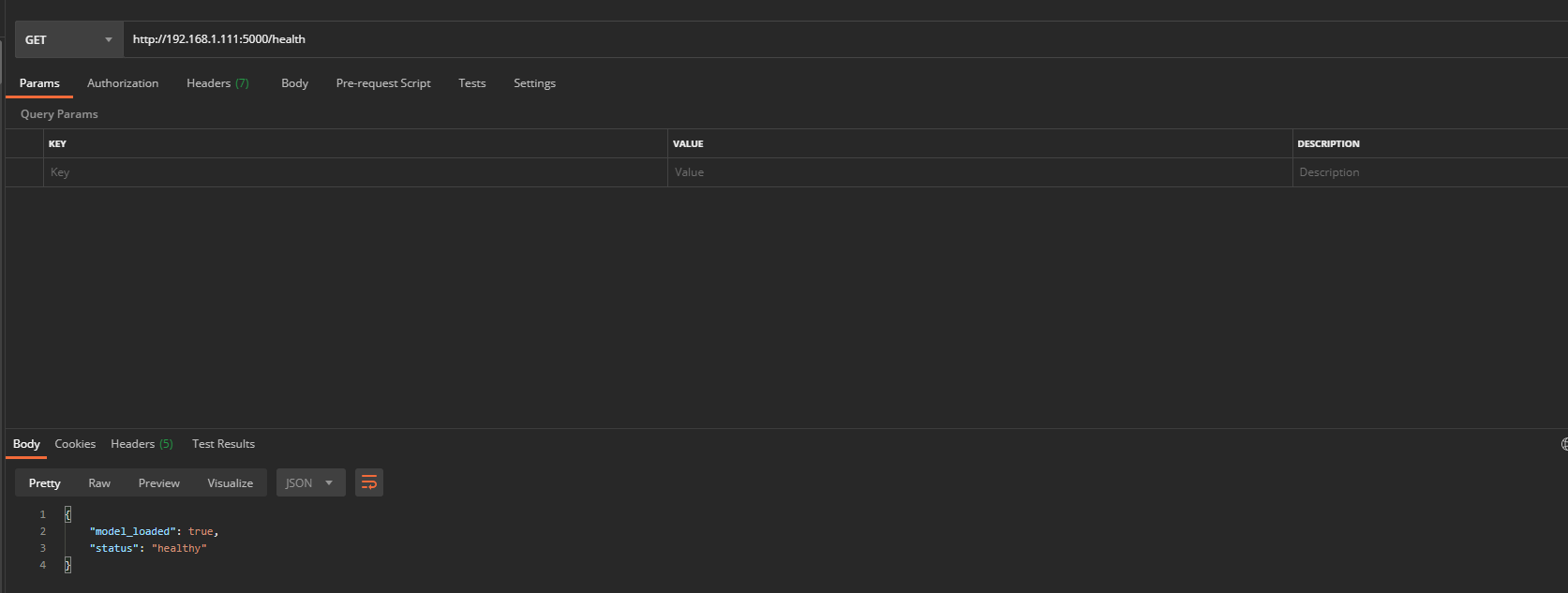

3、其他命令
1、复制容器内部文件到宿主机
docker cp <容器名>:<容器内路径> <宿主机路径>2、复制宿主机文件到容器内部
docker cp <宿主机路径> <容器名>:<容器内路径>