

1、环境搭建
这里使用conda搭建环境
1.1、创建并激活环境
conda create -n ms1 python=3.9
conda activate ms11.2 安装Pytorch等
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple torch torchvision torchaudio
使用conda安装
# 通过conda安装PyTorch CPU版本
conda install pytorch torchvision torchaudio cpuonly -c pytorch
# 或者使用pip安装
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
安装其他必要包
# 安装funasr和modelscope
pip install funasr
pip install modelscope
# 安装huggingface相关库
pip install transformers
pip install huggingface_hub
pip install datasets
# 安装其他常用依赖
pip install soundfile librosa
pip install numpy scipy安装验证
touch check_env.py
# test_installation.py
import torch
import funasr
import modelscope
from huggingface_hub import snapshot_download
from transformers import pipeline
print(f"PyTorch版本: {torch.__version__}")
print(f"PyTorch CUDA可用: {torch.cuda.is_available()}")
print(f"funasr版本: {funasr.__version__}")
print(f"modelscope版本: {modelscope.__version__}")
# 测试简单的transformers pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("I love this product!")
print(f"Transformers测试: {result}")1.3、安装modelscope huggingface huggingface_hub
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -U modelscope huggingface huggingface_hub2、下载源码,准备数据
https://gitcode.com/GitHub_Trending/fun/FunASR?source_module=search_result_repo
解压
unzip FunASR-main.zip
cd FunASR-main
data/list目录,是存放训练数据的
主要文件
train_wav.scp
1 /usr/local/conda/ms1/data/file/1.mp3
2 /usr/local/conda/ms1/data/file/2.mp3
3 /usr/local/conda/ms1/data/file/3.mp3
4 /usr/local/conda/ms1/data/file/4.mp3train_text.txt
1 你好,你在做什么?
2 我在工作,这周还有很多重要的工作没有完成。
3 那你能按时完成吗,需要我提供帮助吗?
4 不用,多谢了,我自己应该可以做完,就是得加班了。val_wav.scp
1 /usr/local/conda/ms1/data/file/1.mp3
2 /usr/local/conda/ms1/data/file/2.mp3
3 /usr/local/conda/ms1/data/file/3.mp3
4 /usr/local/conda/ms1/data/file/4.mp3val_text.txt
1 你好,你在做什么?
2 我在工作,这周还有很多重要的工作没有完成。
3 那你能按时完成吗,需要我提供帮助吗?
4 不用,多谢了,我自己应该可以做完,就是得加班了。3、执行
cd examples/industrial_data_pretraining/paraformer关注脚本:finetune.sh
里面有模型地址,可以改成本地,如下
# Copyright FunASR (https://github.com/alibaba-damo-academy/FunASR). All Rights Reserved.
# MIT License (https://opensource.org/licenses/MIT)
workspace=`pwd`
# which gpu to train or finetune
export CUDA_VISIBLE_DEVICES="0,1"
gpu_num=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}')
# model_name from model_hub, or model_dir in local path
## option 1, download model automatically
model_name_or_model_dir="iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"
## option 2, download model by git
local_path_root=${workspace}/modelscope_models
#mkdir -p ${local_path_root}/${model_name_or_model_dir}
#git clone https://www.modelscope.cn/${model_name_or_model_dir}.git ${local_path_root}/${model_name_or_model_dir}
model_name_or_model_dir=${local_path_root}/${model_name_or_model_dir}
# data dir, which contains: train.json, val.json
data_dir="../../../data/list"
train_data="${data_dir}/train.jsonl"
val_data="${data_dir}/val.jsonl"
# generate train.jsonl and val.jsonl from wav.scp and text.txt
scp2jsonl \
++scp_file_list='["../../../data/list/train_wav.scp", "../../../data/list/train_text.txt"]' \
++data_type_list='["source", "target"]' \
++jsonl_file_out="${train_data}"
scp2jsonl \
++scp_file_list='["../../../data/list/val_wav.scp", "../../../data/list/val_text.txt"]' \
++data_type_list='["source", "target"]' \
++jsonl_file_out="${val_data}"
# exp output dir
output_dir="./outputs"
log_file="${output_dir}/log.txt"
deepspeed_config=${workspace}/../../deepspeed_conf/ds_stage1.json
mkdir -p ${output_dir}
echo "log_file: ${log_file}"
DISTRIBUTED_ARGS="
--nnodes ${WORLD_SIZE:-1} \
--nproc_per_node $gpu_num \
--node_rank ${RANK:-0} \
--master_addr ${MASTER_ADDR:-127.0.0.1} \
--master_port ${MASTER_PORT:-26669}
"
echo $DISTRIBUTED_ARGS
torchrun $DISTRIBUTED_ARGS \
../../../funasr/bin/train_ds.py \
++model="${model_name_or_model_dir}" \
++train_data_set_list="${train_data}" \
++valid_data_set_list="${val_data}" \
++dataset="AudioDataset" \
++dataset_conf.index_ds="IndexDSJsonl" \
++dataset_conf.data_split_num=1 \
++dataset_conf.batch_sampler="BatchSampler" \
++dataset_conf.batch_size=6000 \
++dataset_conf.sort_size=1024 \
++dataset_conf.batch_type="token" \
++dataset_conf.num_workers=4 \
++train_conf.max_epoch=50 \
++train_conf.log_interval=1 \
++train_conf.resume=true \
++train_conf.validate_interval=2000 \
++train_conf.save_checkpoint_interval=2000 \
++train_conf.keep_nbest_models=20 \
++train_conf.avg_nbest_model=10 \
++train_conf.use_deepspeed=false \
++train_conf.deepspeed_config=${deepspeed_config} \
++optim_conf.lr=0.0002 \
++output_dir="${output_dir}" &> ${log_file}finetune.sh最终调用 funasr/bin/train_ds.py
cpu版本
#!/usr/bin/env python3
# -*- encoding: utf-8 -*-
import os
import sys
import torch
import torch.nn as nn
import hydra
import logging
import time
import argparse
from io import BytesIO
from contextlib import nullcontext
import torch.distributed as dist
from omegaconf import DictConfig, OmegaConf
from torch.cuda.amp import autocast, GradScaler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.algorithms.join import Join
from torch.distributed.fsdp.sharded_grad_scaler import ShardedGradScaler
from funasr.train_utils.average_nbest_models import average_checkpoints
from funasr.register import tables
from funasr.optimizers import optim_classes
from funasr.train_utils.trainer_ds import Trainer
from funasr.schedulers import scheduler_classes
from funasr.train_utils.initialize import initialize
from funasr.download.download_model_from_hub import download_model
from funasr.models.lora.utils import mark_only_lora_as_trainable
from funasr.train_utils.set_all_random_seed import set_all_random_seed
from funasr.train_utils.load_pretrained_model import load_pretrained_model
from funasr.utils.misc import prepare_model_dir
from funasr.train_utils.model_summary import model_summary
from funasr import AutoModel
try:
import deepspeed
except:
deepspeed = None
@hydra.main(config_name=None, version_base=None)
def main_hydra(kwargs: DictConfig):
if kwargs.get("debug", False):
import pdb
pdb.set_trace()
assert "model" in kwargs
if "model_conf" not in kwargs:
logging.info("download models from model hub: {}".format(kwargs.get("hub", "ms")))
kwargs = download_model(is_training=kwargs.get("is_training", True), **kwargs)
main(**kwargs)
def main(**kwargs):
# 强制设置为 CPU 模式
kwargs["device"] = "cpu"
# set random seed
set_all_random_seed(kwargs.get("seed", 0))
torch.backends.cudnn.enabled = False # 禁用 cuDNN
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# 禁用 tf32
torch.backends.cuda.matmul.allow_tf32 = False
rank = 0
local_rank = 0
world_size = 1
if local_rank == 0:
tables.print()
# 禁用所有分布式训练
use_ddp = False
use_fsdp = False
use_deepspeed = False
logging.info("Build model, frontend, tokenizer")
# 强制使用 CPU
kwargs["device"] = "cpu"
model = AutoModel(**kwargs)
# save config.yaml
if rank == 0:
prepare_model_dir(**kwargs)
# parse kwargs
kwargs = model.kwargs
kwargs["device"] = "cpu" # 确保设备是 CPU
tokenizer = kwargs["tokenizer"]
frontend = kwargs["frontend"]
model = model.model
del kwargs["model"]
# freeze_param
freeze_param = kwargs.get("freeze_param", None)
if freeze_param is not None:
if "," in freeze_param:
freeze_param = eval(freeze_param)
if not isinstance(freeze_param, (list, tuple)):
freeze_param = (freeze_param,)
logging.info("freeze_param is not None: %s", freeze_param)
for t in freeze_param:
for k, p in model.named_parameters():
if k.startswith(t + ".") or k == t:
logging.info(f"Setting {k}.requires_grad = False")
p.requires_grad = False
if local_rank == 0:
logging.info(f"{model_summary(model)}")
trainer = Trainer(
rank=rank,
local_rank=local_rank,
world_size=world_size,
use_ddp=use_ddp,
use_fsdp=use_fsdp,
device=kwargs["device"],
excludes=kwargs.get("excludes", None),
output_dir=kwargs.get("output_dir", "./exp"),
**kwargs.get("train_conf"),
)
model = trainer.warp_model(model, **kwargs)
# 确保设备是 CPU
kwargs["device"] = "cpu"
trainer.device = "cpu"
model, optim, scheduler = trainer.warp_optim_scheduler(model, **kwargs)
# 将模型移动到 CPU(虽然默认已经在 CPU 上,但为了保险)
model = model.to("cpu")
# dataset
logging.info("Build dataloader")
dataloader_class = tables.dataloader_classes.get(
kwargs["dataset_conf"].get("dataloader", "DataloaderMapStyle")
)
dataloader = dataloader_class(**kwargs)
# 禁用混合精度训练(CPU 不支持)
scaler = None
trainer.resume_checkpoint(
model=model,
optim=optim,
scheduler=scheduler,
scaler=scaler,
)
early_stopping_patience = kwargs.get("train_conf", {}).get("early_stopping_patience", 0)
best_val_loss = float("inf")
epochs_no_improve = 0
dataloader_tr, dataloader_val = None, None
for epoch in range(trainer.start_epoch, trainer.max_epoch):
time1 = time.perf_counter()
for data_split_i in range(trainer.start_data_split_i, dataloader.data_split_num):
time_slice_i = time.perf_counter()
dataloader_tr, dataloader_val = dataloader.build_iter(
epoch, data_split_i=data_split_i, start_step=trainer.start_step
)
trainer.train_epoch(
model=model,
optim=optim,
scheduler=scheduler,
scaler=scaler,
dataloader_train=dataloader_tr,
dataloader_val=dataloader_val,
epoch=epoch,
data_split_i=data_split_i,
data_split_num=dataloader.data_split_num,
start_step=trainer.start_step,
)
trainer.start_step = 0
# 清理内存(如果有 GPU 内存占用的话)
if torch.cuda.is_available():
torch.cuda.empty_cache()
time_escaped = (time.perf_counter() - time_slice_i) / 3600.0
logging.info(
f"\n\nrank: {local_rank}, "
f"time_escaped_epoch: {time_escaped:.3f} hours, "
f"estimated to finish {dataloader.data_split_num} data_slices, remaining: {dataloader.data_split_num-data_split_i} slices, {(dataloader.data_split_num-data_split_i)*time_escaped:.3f} hours, "
f"epoch: {trainer.max_epoch - epoch} epochs, {((trainer.max_epoch - epoch - 1)*dataloader.data_split_num + dataloader.data_split_num-data_split_i)*time_escaped:.3f} hours\n"
)
trainer.start_data_split_i = 0
trainer.validate_epoch(model=model, dataloader_val=dataloader_val, epoch=epoch + 1)
current_val = trainer.val_loss_avg
if current_val < best_val_loss:
logging.info(f"current_val: {current_val}, best_val_loss: {best_val_loss}")
best_val_loss = current_val
epochs_no_improve = 0
else:
epochs_no_improve += 1
logging.info(f"No val_loss improvement for {epochs_no_improve}/{early_stopping_patience} epochs")
if early_stopping_patience > 0 and epochs_no_improve >= early_stopping_patience:
logging.info(f"Early stopping triggered at epoch {epoch+1}")
break
trainer.step_in_epoch = 0
trainer.save_checkpoint(
epoch + 1, model=model, optim=optim, scheduler=scheduler, scaler=scaler
)
time2 = time.perf_counter()
time_escaped = (time2 - time1) / 3600.0
logging.info(
f"\n\nrank: {local_rank}, "
f"time_escaped_epoch: {time_escaped:.3f} hours, "
f"estimated to finish {trainer.max_epoch} "
f"epoch: {(trainer.max_epoch - epoch) * time_escaped:.3f} hours\n"
)
trainer.train_acc_avg = 0.0
trainer.train_loss_avg = 0.0
if trainer.rank == 0:
average_checkpoints(
trainer.output_dir, trainer.avg_nbest_model, use_deepspeed=trainer.use_deepspeed
)
trainer.close()
if __name__ == "__main__":
main_hydra()GPU版本,默认版本
#!/usr/bin/env python3
# -*- encoding: utf-8 -*-
import os
import sys
import torch
import torch.nn as nn
import hydra
import logging
import time
import argparse
from io import BytesIO
from contextlib import nullcontext
import torch.distributed as dist
from omegaconf import DictConfig, OmegaConf
from torch.cuda.amp import autocast, GradScaler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.algorithms.join import Join
from torch.distributed.fsdp.sharded_grad_scaler import ShardedGradScaler
from funasr.train_utils.average_nbest_models import average_checkpoints
from funasr.register import tables
from funasr.optimizers import optim_classes
from funasr.train_utils.trainer_ds import Trainer
from funasr.schedulers import scheduler_classes
from funasr.train_utils.initialize import initialize
from funasr.download.download_model_from_hub import download_model
from funasr.models.lora.utils import mark_only_lora_as_trainable
from funasr.train_utils.set_all_random_seed import set_all_random_seed
from funasr.train_utils.load_pretrained_model import load_pretrained_model
from funasr.utils.misc import prepare_model_dir
from funasr.train_utils.model_summary import model_summary
from funasr import AutoModel
try:
import deepspeed
except:
deepspeed = None
@hydra.main(config_name=None, version_base=None)
def main_hydra(kwargs: DictConfig):
if kwargs.get("debug", False):
import pdb
pdb.set_trace()
assert "model" in kwargs
if "model_conf" not in kwargs:
logging.info("download models from model hub: {}".format(kwargs.get("hub", "ms")))
kwargs = download_model(is_training=kwargs.get("is_training", True), **kwargs)
main(**kwargs)
def main(**kwargs):
# set random seed
set_all_random_seed(kwargs.get("seed", 0))
torch.backends.cudnn.enabled = kwargs.get("cudnn_enabled", torch.backends.cudnn.enabled)
torch.backends.cudnn.benchmark = kwargs.get("cudnn_benchmark", torch.backends.cudnn.benchmark)
torch.backends.cudnn.deterministic = kwargs.get("cudnn_deterministic", True)
# open tf32
torch.backends.cuda.matmul.allow_tf32 = kwargs.get("enable_tf32", True)
rank = int(os.environ.get("RANK", 0))
local_rank = int(os.environ.get("LOCAL_RANK", 0))
world_size = int(os.environ.get("WORLD_SIZE", 1))
if local_rank == 0:
tables.print()
use_ddp = world_size > 1
use_fsdp = kwargs.get("use_fsdp", False)
use_deepspeed = kwargs.get("use_deepspeed", False)
if use_deepspeed:
logging.info(f"use_deepspeed: {use_deepspeed}")
deepspeed.init_distributed(dist_backend=kwargs.get("backend", "nccl"))
elif use_ddp or use_fsdp:
logging.info(f"use_ddp: {use_ddp}, use_fsdp: {use_fsdp}")
dist.init_process_group(
backend=kwargs.get("backend", "nccl"),
init_method="env://",
)
torch.cuda.set_device(local_rank)
# rank = dist.get_rank()
logging.info("Build model, frontend, tokenizer")
device = kwargs.get("device", "cuda")
kwargs["device"] = "cpu"
model = AutoModel(**kwargs)
# save config.yaml
if rank == 0:
prepare_model_dir(**kwargs)
# parse kwargs
kwargs = model.kwargs
kwargs["device"] = device
tokenizer = kwargs["tokenizer"]
frontend = kwargs["frontend"]
model = model.model
del kwargs["model"]
# freeze_param
freeze_param = kwargs.get("freeze_param", None)
if freeze_param is not None:
if "," in freeze_param:
freeze_param = eval(freeze_param)
if not isinstance(freeze_param, (list, tuple)):
freeze_param = (freeze_param,)
logging.info("freeze_param is not None: %s", freeze_param)
for t in freeze_param:
for k, p in model.named_parameters():
if k.startswith(t + ".") or k == t:
logging.info(f"Setting {k}.requires_grad = False")
p.requires_grad = False
if local_rank == 0:
logging.info(f"{model_summary(model)}")
trainer = Trainer(
rank=rank,
local_rank=local_rank,
world_size=world_size,
use_ddp=use_ddp,
use_fsdp=use_fsdp,
device=kwargs["device"],
excludes=kwargs.get("excludes", None),
output_dir=kwargs.get("output_dir", "./exp"),
**kwargs.get("train_conf"),
)
model = trainer.warp_model(model, **kwargs)
kwargs["device"] = int(os.environ.get("LOCAL_RANK", 0))
trainer.device = int(os.environ.get("LOCAL_RANK", 0))
model, optim, scheduler = trainer.warp_optim_scheduler(model, **kwargs)
# dataset
logging.info("Build dataloader")
dataloader_class = tables.dataloader_classes.get(
kwargs["dataset_conf"].get("dataloader", "DataloaderMapStyle")
)
dataloader = dataloader_class(**kwargs)
# dataloader_tr, dataloader_val = dataloader_class(**kwargs)
scaler = GradScaler(enabled=True) if trainer.use_fp16 else None
scaler = ShardedGradScaler(enabled=trainer.use_fp16) if trainer.use_fsdp else scaler
trainer.resume_checkpoint(
model=model,
optim=optim,
scheduler=scheduler,
scaler=scaler,
)
early_stopping_patience = kwargs.get("train_conf", {}).get("early_stopping_patience", 0)
best_val_loss = float("inf")
epochs_no_improve = 0
dataloader_tr, dataloader_val = None, None
for epoch in range(trainer.start_epoch, trainer.max_epoch):
time1 = time.perf_counter()
for data_split_i in range(trainer.start_data_split_i, dataloader.data_split_num):
time_slice_i = time.perf_counter()
dataloader_tr, dataloader_val = dataloader.build_iter(
epoch, data_split_i=data_split_i, start_step=trainer.start_step
)
trainer.train_epoch(
model=model,
optim=optim,
scheduler=scheduler,
scaler=scaler,
dataloader_train=dataloader_tr,
dataloader_val=dataloader_val,
epoch=epoch,
data_split_i=data_split_i,
data_split_num=dataloader.data_split_num,
start_step=trainer.start_step,
)
trainer.start_step = 0
device = next(model.parameters()).device
if device.type == "cuda":
with torch.cuda.device(device):
torch.cuda.empty_cache()
time_escaped = (time.perf_counter() - time_slice_i) / 3600.0
logging.info(
f"\n\nrank: {local_rank}, "
f"time_escaped_epoch: {time_escaped:.3f} hours, "
f"estimated to finish {dataloader.data_split_num} data_slices, remaining: {dataloader.data_split_num-data_split_i} slices, {(dataloader.data_split_num-data_split_i)*time_escaped:.3f} hours, "
f"epoch: {trainer.max_epoch - epoch} epochs, {((trainer.max_epoch - epoch - 1)*dataloader.data_split_num + dataloader.data_split_num-data_split_i)*time_escaped:.3f} hours\n"
)
trainer.start_data_split_i = 0
trainer.validate_epoch(model=model, dataloader_val=dataloader_val, epoch=epoch + 1)
current_val = trainer.val_loss_avg
if current_val < best_val_loss:
logging.info(f"current_val: {current_val}, best_val_loss: {best_val_loss}")
best_val_loss = current_val
epochs_no_improve = 0
else:
epochs_no_improve += 1
logging.info(f"No val_loss improvement for {epochs_no_improve}/{early_stopping_patience} epochs")
if early_stopping_patience > 0 and epochs_no_improve >= early_stopping_patience:
logging.info(f"Early stopping triggered at epoch {epoch+1}")
break
trainer.step_in_epoch = 0
trainer.save_checkpoint(
epoch + 1, model=model, optim=optim, scheduler=scheduler, scaler=scaler
)
time2 = time.perf_counter()
time_escaped = (time2 - time1) / 3600.0
logging.info(
f"\n\nrank: {local_rank}, "
f"time_escaped_epoch: {time_escaped:.3f} hours, "
f"estimated to finish {trainer.max_epoch} "
f"epoch: {(trainer.max_epoch - epoch) * time_escaped:.3f} hours\n"
)
trainer.train_acc_avg = 0.0
trainer.train_loss_avg = 0.0
if trainer.rank == 0:
average_checkpoints(
trainer.output_dir, trainer.avg_nbest_model, use_deepspeed=trainer.use_deepspeed
)
trainer.close()
if __name__ == "__main__":
main_hydra()3.1 执行
bash finetune.sh
查看日志
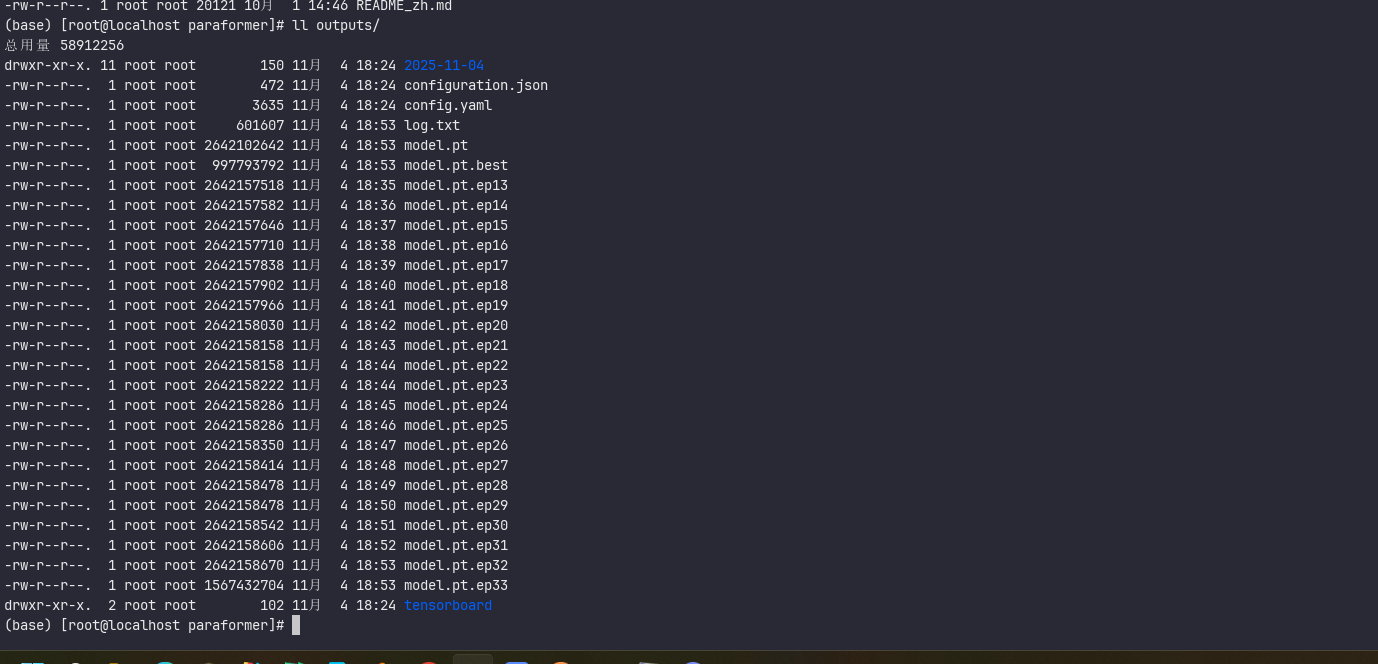
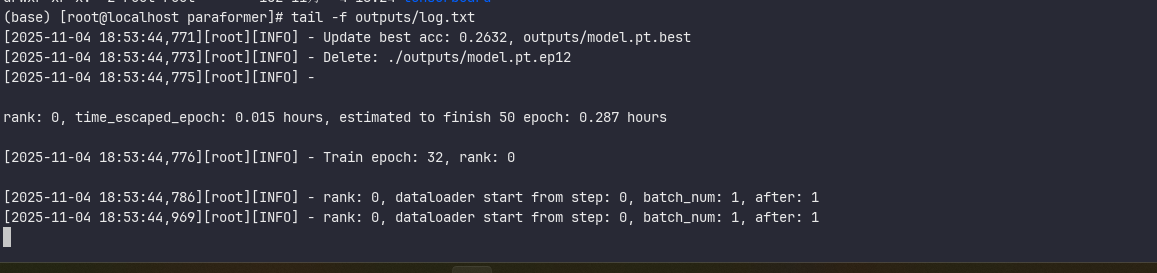
4、详细查看系统说明
docs/tutorial/README_zh.md
5、问题
5.1、average_nbest_models.py内部代码错误
train_ds.py内部调用了average_nbest_models.py的average_checkpoints,获取最新的10(avg_nbest_model)个模型,做平均
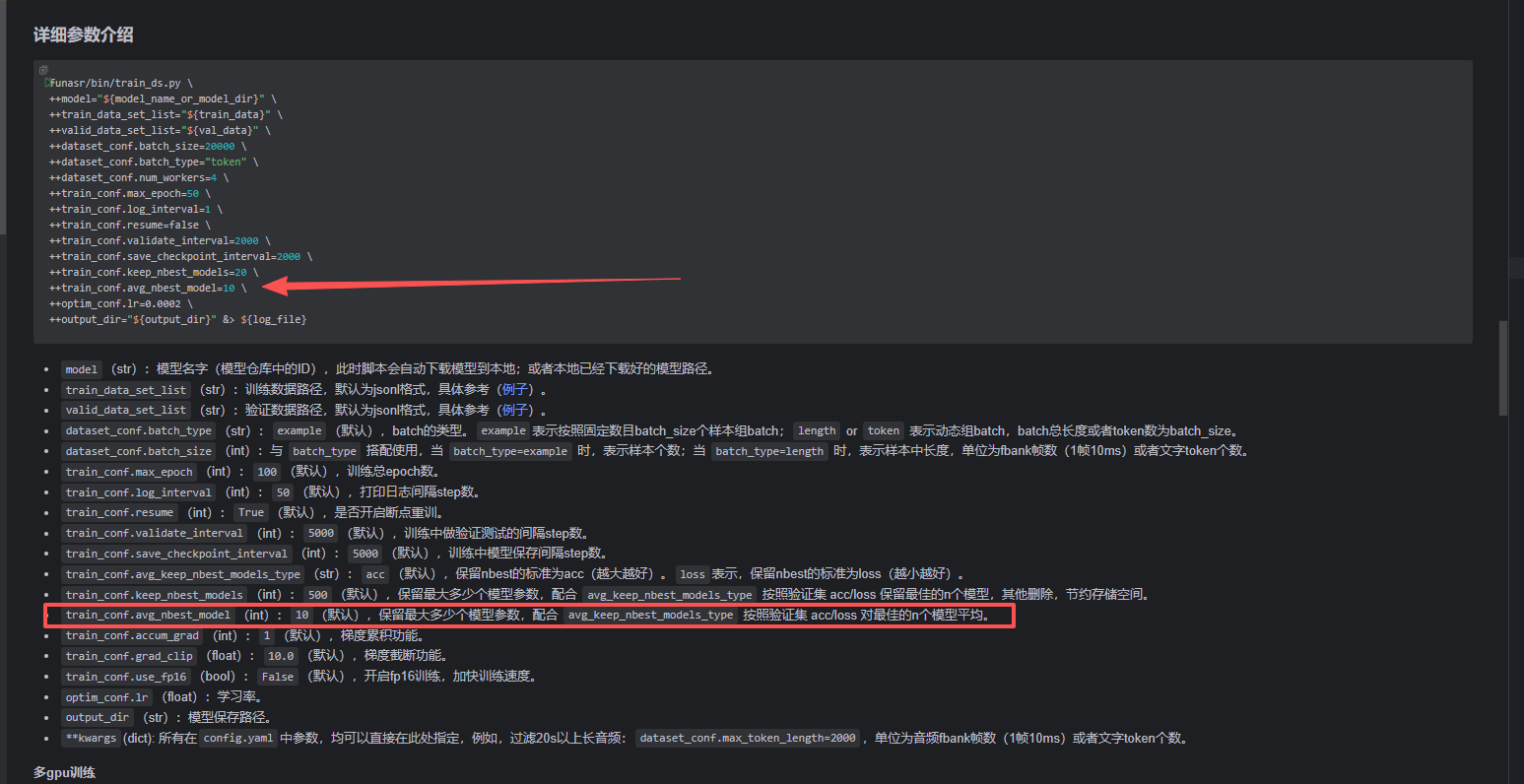
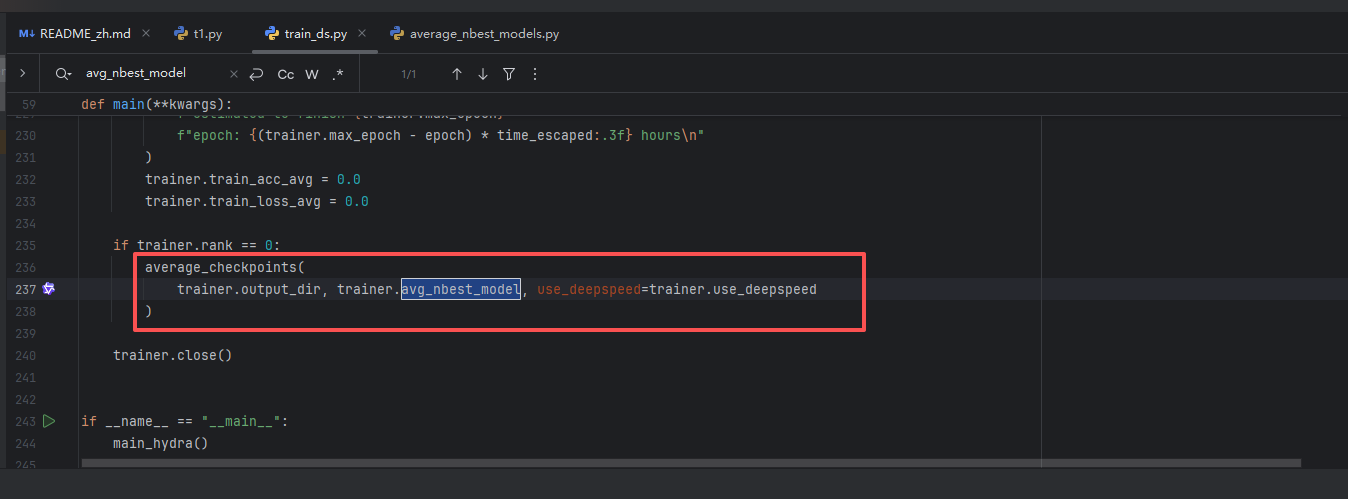
但是average_nbest_models.py的average_checkpoints方法内部有错误
catch中,使用了上面局部变量checkpoint,checkpoint如果实例化失败,为null的情况下,就会报错
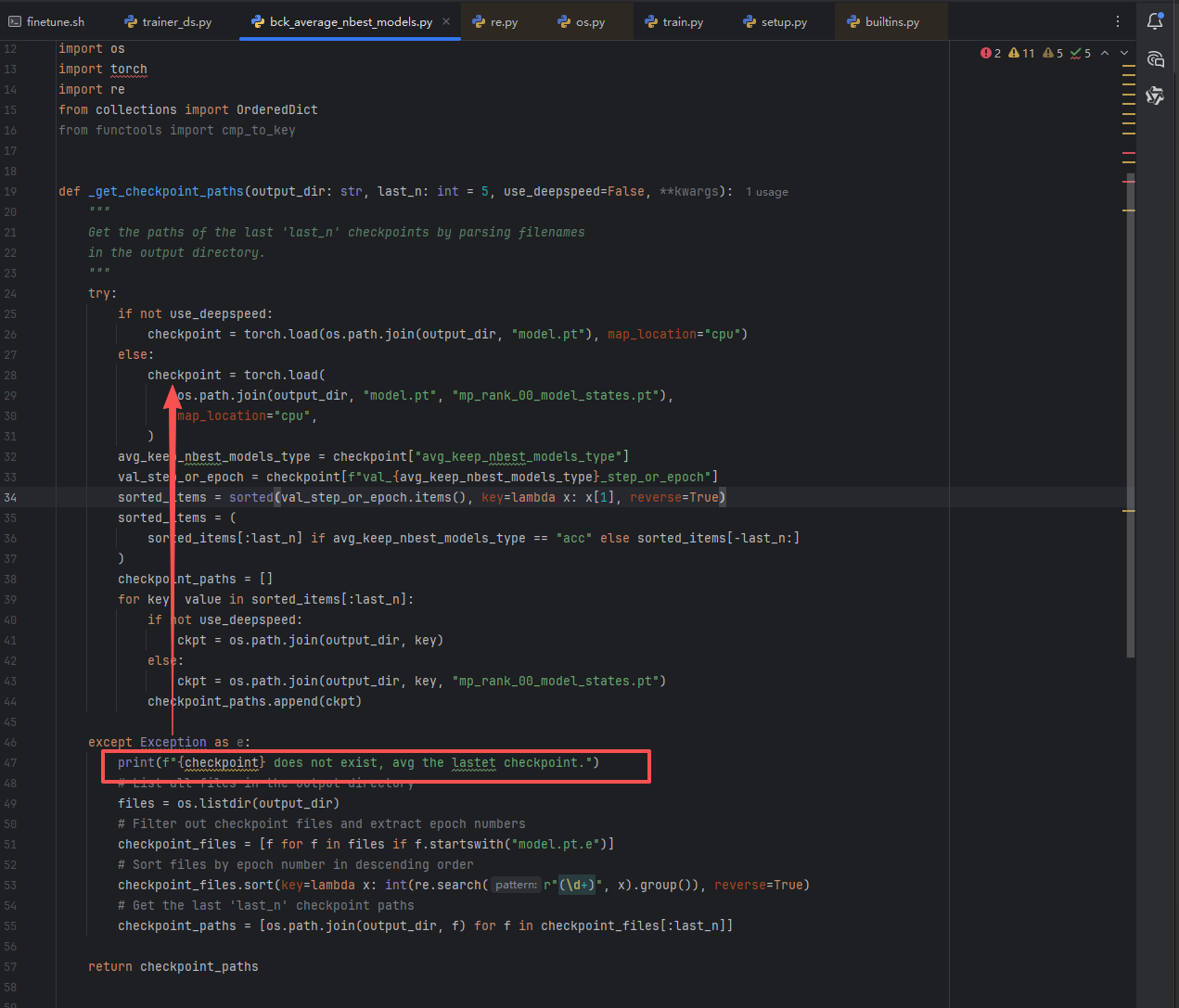
修复1
import logging
from pathlib import Path
from typing import Optional
from typing import Sequence
from typing import Union
import warnings
import os
from io import BytesIO
import torch
from typing import Collection
import os
import torch
import re
from collections import OrderedDict
from functools import cmp_to_key
def _get_checkpoint_paths(output_dir: str, last_n: int = 5, use_deepspeed=False, **kwargs):
"""
Get the paths of the last 'last_n' checkpoints by parsing filenames
in the output directory.
"""
try:
if not use_deepspeed:
checkpoint = torch.load(os.path.join(output_dir, "model.pt"), map_location="cpu")
else:
checkpoint = torch.load(
os.path.join(output_dir, "model.pt", "mp_rank_00_model_states.pt"),
map_location="cpu",
)
avg_keep_nbest_models_type = checkpoint["avg_keep_nbest_models_type"]
val_step_or_epoch = checkpoint[f"val_{avg_keep_nbest_models_type}_step_or_epoch"]
sorted_items = sorted(val_step_or_epoch.items(), key=lambda x: x[1], reverse=True)
sorted_items = (
sorted_items[:last_n] if avg_keep_nbest_models_type == "acc" else sorted_items[-last_n:]
)
checkpoint_paths = []
for key, value in sorted_items[:last_n]:
if not use_deepspeed:
ckpt = os.path.join(output_dir, key)
else:
ckpt = os.path.join(output_dir, key, "mp_rank_00_model_states.pt")
checkpoint_paths.append(ckpt)
except Exception as e:
logging.warning(f"Failed to load best model info: {e}. Using epoch-based checkpoint selection.")
# List all files in the output directory
files = os.listdir(output_dir)
# Filter out checkpoint files and extract epoch numbers
checkpoint_files = [f for f in files if f.startswith("model.pt.e")]
# Sort files by epoch number in descending order
checkpoint_files.sort(key=lambda x: int(re.search(r"(\d+)", x).group()), reverse=True)
# Get the last 'last_n' checkpoint paths
checkpoint_paths = [os.path.join(output_dir, f) for f in checkpoint_files[:last_n]]
return checkpoint_paths
@torch.no_grad()
def average_checkpoints(output_dir: str, last_n: int = 5, **kwargs):
"""
Average the last 'last_n' checkpoints' model state_dicts.
If a tensor is of type torch.int, perform sum instead of average.
"""
checkpoint_paths = _get_checkpoint_paths(output_dir, last_n, **kwargs)
print(f"average_checkpoints: {checkpoint_paths}")
state_dicts = []
# Load state_dicts from checkpoints
for path in checkpoint_paths:
if os.path.isfile(path):
state_dicts.append(torch.load(path, map_location="cpu")["state_dict"])
else:
print(f"Checkpoint file {path} not found.")
# Check if we have any state_dicts to average
if len(state_dicts) < 1:
print("No checkpoints found for averaging.")
return
# Average or sum weights
avg_state_dict = OrderedDict()
for key in state_dicts[0].keys():
tensors = [state_dict[key].cpu() for state_dict in state_dicts]
# Check the type of the tensor
if str(tensors[0].dtype).startswith("torch.int"):
# Perform sum for integer tensors
summed_tensor = sum(tensors)
avg_state_dict[key] = summed_tensor
else:
# Perform average for other types of tensors
stacked_tensors = torch.stack(tensors)
avg_state_dict[key] = torch.mean(stacked_tensors, dim=0)
checkpoint_outpath = os.path.join(output_dir, f"model.pt.avg{last_n}")
torch.save({"state_dict": avg_state_dict}, checkpoint_outpath)
return checkpoint_outpath
修复2
import logging
from pathlib import Path
from typing import Optional, Sequence, Union, Collection
import warnings
import os
import re
from collections import OrderedDict
from functools import cmp_to_key
import torch
def _get_checkpoint_paths(output_dir: str, last_n: int = 5, use_deepspeed=False, **kwargs):
"""
Get the paths of the last 'last_n' checkpoints by parsing filenames
in the output directory.
"""
checkpoint_paths = []
try:
# 尝试加载主模型文件来获取最佳模型信息
model_path = os.path.join(output_dir, "model.pt")
if use_deepspeed:
model_path = os.path.join(output_dir, "model.pt", "mp_rank_00_model_states.pt")
if not os.path.exists(model_path):
raise FileNotFoundError(f"Model file not found: {model_path}")
checkpoint = torch.load(model_path, map_location="cpu")
# 检查必要的键是否存在
if "avg_keep_nbest_models_type" not in checkpoint:
raise KeyError("avg_keep_nbest_models_type not found in checkpoint")
avg_keep_nbest_models_type = checkpoint["avg_keep_nbest_models_type"]
val_key = f"val_{avg_keep_nbest_models_type}_step_or_epoch"
if val_key not in checkpoint:
raise KeyError(f"{val_key} not found in checkpoint")
val_step_or_epoch = checkpoint[val_key]
sorted_items = sorted(val_step_or_epoch.items(), key=lambda x: x[1], reverse=True)
sorted_items = (
sorted_items[:last_n] if avg_keep_nbest_models_type == "acc" else sorted_items[-last_n:]
)
for key, value in sorted_items[:last_n]:
if not use_deepspeed:
ckpt = os.path.join(output_dir, key)
else:
ckpt = os.path.join(output_dir, key, "mp_rank_00_model_states.pt")
checkpoint_paths.append(ckpt)
except Exception as e:
logging.warning(f"Failed to load best model info: {e}. Using epoch-based checkpoint selection.")
# 回退方案:按epoch编号选择最新的检查点
try:
files = os.listdir(output_dir)
# 匹配 model.pt.epX 格式的文件
checkpoint_files = [f for f in files if re.match(r"model\.pt\.ep\d+", f)]
if not checkpoint_files:
logging.warning(f"No epoch-based checkpoint files found in {output_dir}")
return []
# 按epoch编号排序
checkpoint_files.sort(key=lambda x: int(re.search(r"ep(\d+)", x).group(1)), reverse=True)
checkpoint_paths = [os.path.join(output_dir, f) for f in checkpoint_files[:last_n]]
except Exception as sort_error:
logging.error(f"Error during epoch-based checkpoint selection: {sort_error}")
return []
return checkpoint_paths
@torch.no_grad()
def average_checkpoints(output_dir: str, last_n: int = 5, **kwargs):
"""
Average the last 'last_n' checkpoints' model state_dicts.
If a tensor is of type torch.int, perform sum instead of average.
"""
checkpoint_paths = _get_checkpoint_paths(output_dir, last_n, **kwargs)
print(f"average_checkpoints: {checkpoint_paths}")
if not checkpoint_paths:
print("No checkpoint paths found for averaging.")
return None
state_dicts = []
# Load state_dicts from checkpoints
for path in checkpoint_paths:
if os.path.isfile(path):
try:
checkpoint = torch.load(path, map_location="cpu")
if "state_dict" in checkpoint:
state_dicts.append(checkpoint["state_dict"])
else:
print(f"Checkpoint file {path} does not contain 'state_dict' key")
except Exception as e:
print(f"Failed to load checkpoint {path}: {e}")
else:
print(f"Checkpoint file {path} not found.")
# Check if we have any state_dicts to average
if len(state_dicts) < 1:
print("No valid checkpoints found for averaging.")
return None
# Average or sum weights
avg_state_dict = OrderedDict()
for key in state_dicts[0].keys():
tensors = [state_dict[key].cpu() for state_dict in state_dicts]
# Check the type of the tensor
if str(tensors[0].dtype).startswith("torch.int"):
# Perform sum for integer tensors
summed_tensor = sum(tensors)
avg_state_dict[key] = summed_tensor
else:
# Perform average for other types of tensors
stacked_tensors = torch.stack(tensors)
avg_state_dict[key] = torch.mean(stacked_tensors, dim=0)
checkpoint_outpath = os.path.join(output_dir, f"model.pt.avg{last_n}")
torch.save({"state_dict": avg_state_dict}, checkpoint_outpath)
print(f"Average model saved to: {checkpoint_outpath}")
return checkpoint_outpath