1、环境安装
需要安装下面环境:
1、python>=3.8
2、torch>=1.13
3、torchaudio
4、Funasr
5、modelscope、huggingface、huggingface_hub
6、flask
7、ffmpeg
1.1、python3安装
根据步骤安装即可

1.2、安装 PyTorch 和 torchaudio
方法一:使用 pip 安装(推荐)
打开命令提示符(CMD)。
根据你的需求,执行以下任一命令:
安装CPU版本(如果你的电脑没有NVIDIA显卡或不需要GPU加速):
bash
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple torch torchvision torchaudio安装GPU版本(支持CUDA,如果你的电脑有NVIDIA显卡):
bash
# 安装支持CUDA的版本
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple torch torchvision torchaudio方法二:使用 Conda 安装(如果你使用 Anaconda 或 Miniconda)
打开 Anaconda Prompt 或命令提示符。
执行以下命令:
bash
conda install pytorch torchvision torchaudio -c pytorch3️⃣ 验证安装
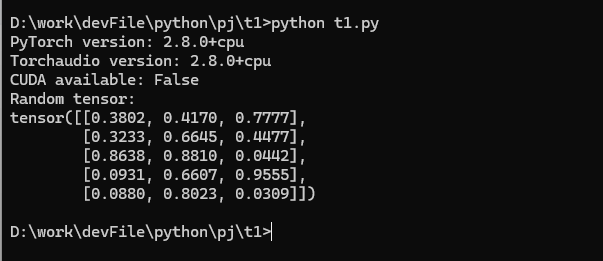
安装完成后,需要确认所有组件已正确安装。
打开命令提示符。
输入
python进入 Python 交互模式。逐行输入并执行以下代码:
python
import torch
import torchaudio
# 检查 PyTorch 版本
print("PyTorch version:", torch.__version__)
# 检查 torchaudio 版本
print("Torchaudio version:", torchaudio.__version__)
# 验证 CUDA 是否可用(如果你安装了GPU版本)
print("CUDA available:", torch.cuda.is_available())
# 创建一个简单的张量测试
x = torch.rand(5, 3)
print("Random tensor:")
print(x)如果输出显示 PyTorch 版本 ≥1.13,torchaudio 版本正确,并且能正常创建张量,则说明安装成功
遇见问题
1、pip版本过低,需要升级
WARNING: You are using pip version 20.2.3; however, version 25.2 is available.
You should consider upgrading via the 'c:\program files\python\python.exe -m pip install --upgrade pip' command.方法一:使用警告中提供的命令(推荐)
bash
"c:\program files\python\python.exe" -m pip install --upgrade pip方法二:直接使用 pip 升级
bash
pip install --upgrade pip
1.3、安装funasr
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -U funasr
1.4 安装modelscope huggingface huggingface_hub
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -U modelscope huggingface huggingface_hub
1.5 安装flask
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple flask
1.6 安装ffmpeg
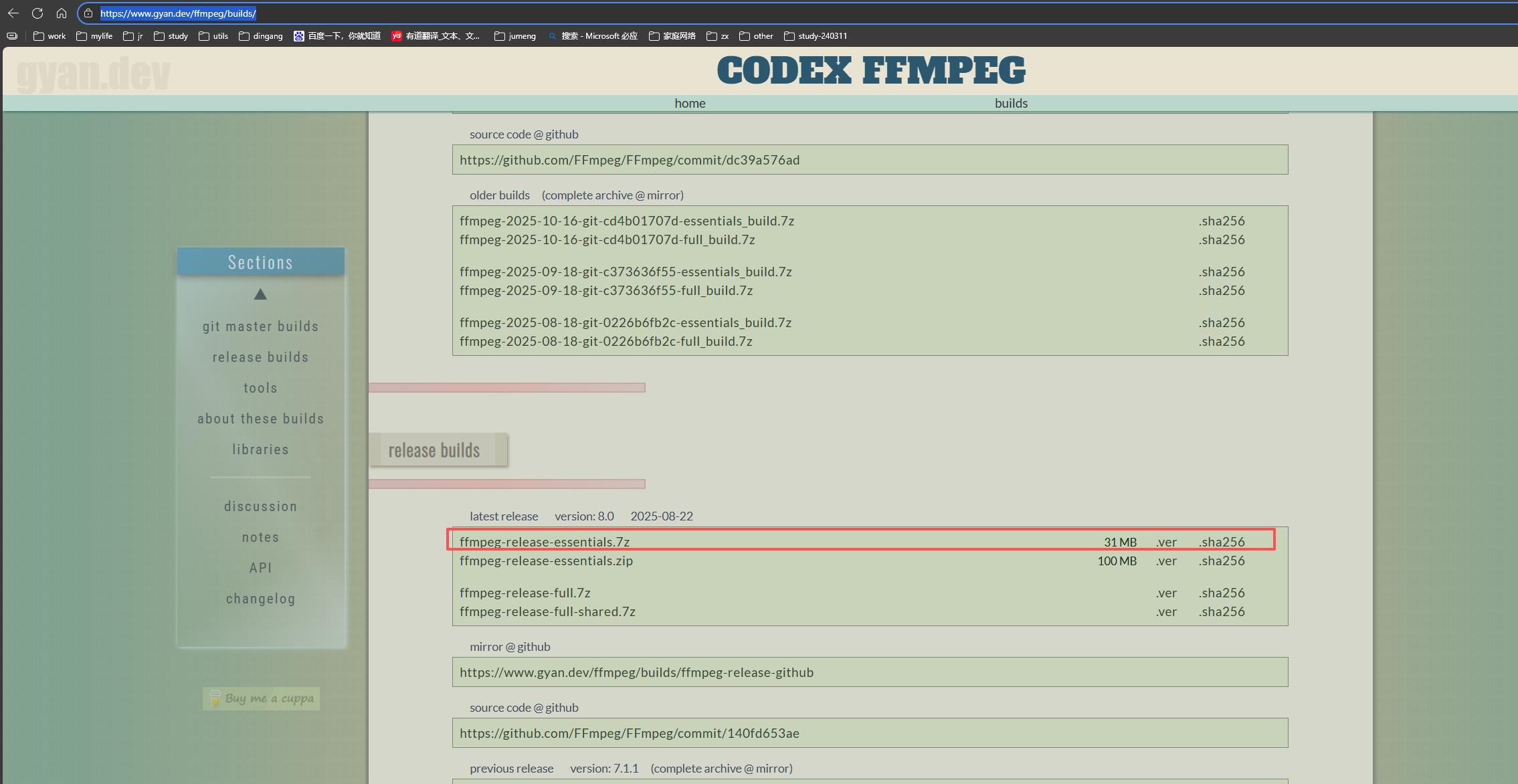
官网下载,直接解压,添加系统环境配置即可:https://www.gyan.dev/ffmpeg/builds/
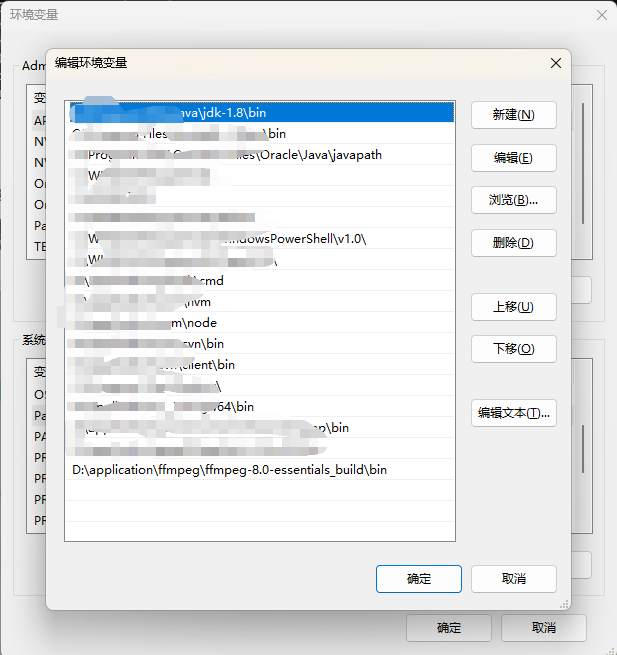
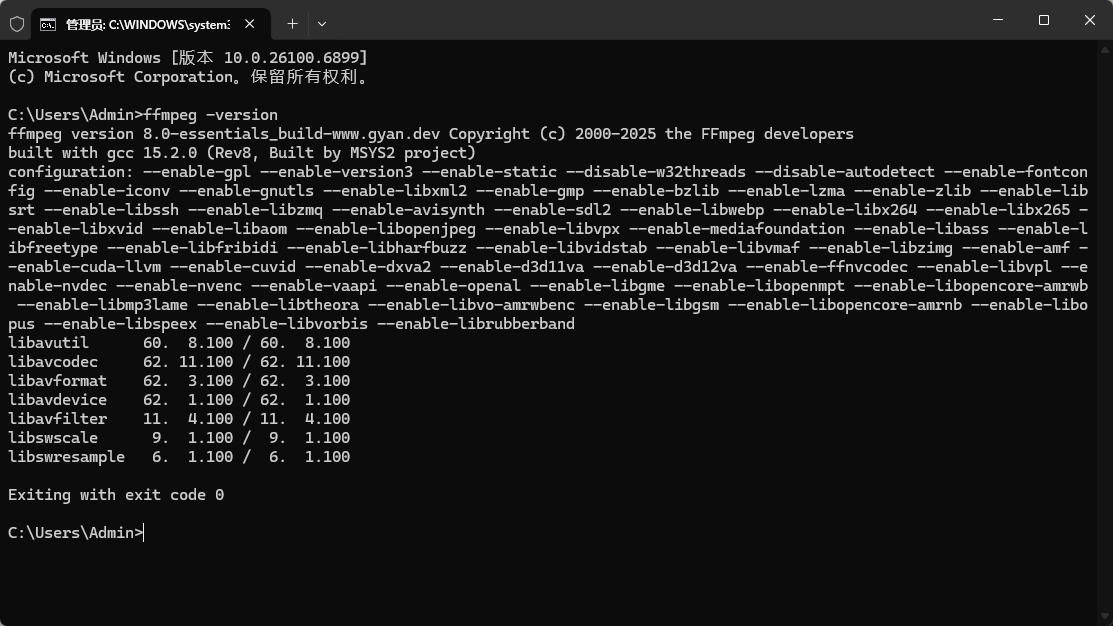
2、下载模型
创建文件夹:models

modelscope download --model iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn --local_dir ./models/iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn
modelscope download --model iic/speech_fsmn_vad_zh-cn-16k-common-pytorch --local_dir ./models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch
modelscope download --model iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch --local_dir ./models/iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch
modelscope download --model iic/speech_campplus_sv_zh-cn_16k-common --local_dir ./models/iic/speech_campplus_sv_zh-cn_16k-common1、iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn:语音转文字模型
2、iic/speech_fsmn_vad_zh-cn-16k-common-pytorch:在音频流中精准定位语音的开始和结束,区分语音与非语音(如静音或噪音)。 一个敏感的哨兵,负责判断什么时候开始听,什么时候可以休息。
3、iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch:为识别出的纯文本自动添加标点符号(如句号、逗号),大幅提升文本的可读性。 一位专业的编辑,负责将杂乱无章的文字整理成条理清晰的段落。
4、iic/speech_campplus_sv_zh-cn_16k-common:(说话人识别/分离) 识别或区分音频中不同的说话人,实现分角色转写。 一个精明的侦探,能根据声音特征分辨出"这句话是谁说的"。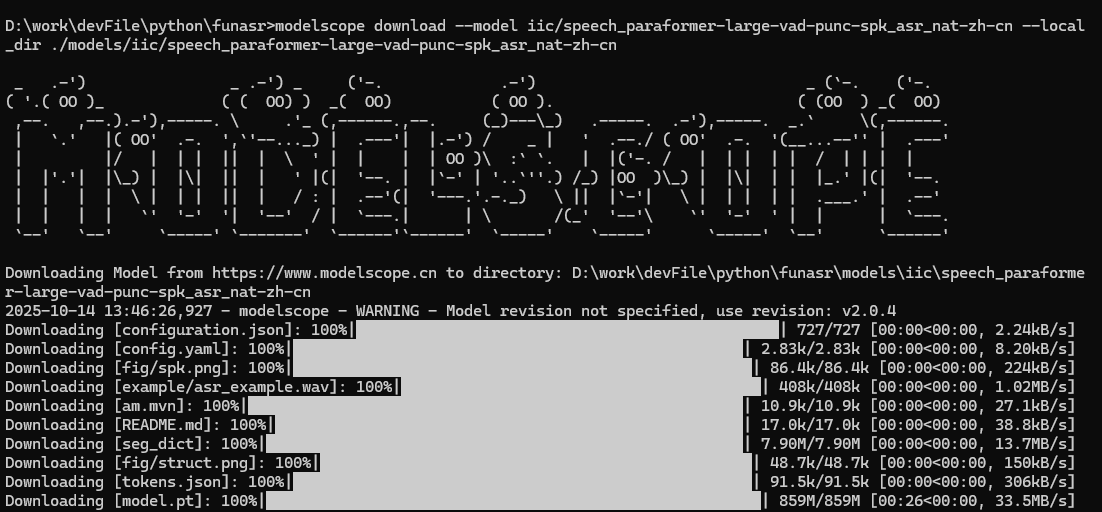
3、创建python代码,并运行
utils.py
from flask import jsonify
import logging
from sys import stdout
# 日志配置类
class LogFactory:
# 配置日志
log = logging.getLogger('waitress')
# 日志级别
log.setLevel(logging.INFO)
# 清除现有处理器
log.handlers = []
# 添加控制台处理器
handler = logging.StreamHandler(stdout)
handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s : %(message)s'))
log.addHandler(handler)
# 防止日志传递给根 logger
log.propagate = False
# 请求结果
class R:
@staticmethod
def ok(data, msg):
if data is None:
return jsonify({"code": 0, "msg": msg, "data": None})
else:
return jsonify({"code": 0, "msg": msg, "data": data})
@staticmethod
def fail(msg):
return jsonify({"code": 1, "msg": msg, "data": None})
@staticmethod
def failCode(code, msg):
return jsonify({"code": code, "msg": msg, "data": None})
voice_server.py
注意模型路径,和暴露端口
from flask import Flask, request
from funasr import AutoModel
import os
import numpy as np
from utils import R
app = Flask(__name__)
MODEL_DIR = "D:/work/devFile/python/funasr/models"
# MODEL_DIR = "./models"
# AutoModel 构造函数参数是一个字典
model = AutoModel(
model=os.path.join(MODEL_DIR, "iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn"),
# vad_model (语音活动检测) 在音频流中精准定位语音的开始和结束,区分语音与非语音(如静音或噪音)。 一个敏感的哨兵,负责判断什么时候开始听,什么时候可以休息。
vad_model=os.path.join(MODEL_DIR, "iic/speech_fsmn_vad_zh-cn-16k-common-pytorch"),
# punc_model (标点预测) 为识别出的纯文本自动添加标点符号(如句号、逗号),大幅提升文本的可读性。 一位专业的编辑,负责将杂乱无章的文字整理成条理清晰的段落。
punc_model=os.path.join(MODEL_DIR, "iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch"),
# spk_model (说话人识别/分离) 识别或区分音频中不同的说话人,实现分角色转写。 一个精明的侦探,能根据声音特征分辨出"这句话是谁说的"。
spk_model=os.path.join(MODEL_DIR, "iic/speech_campplus_sv_zh-cn_16k-common"),
model_revision="v2.0.4",
disable_update=True,
log_level="DEBUG",
# device="cpu"
device="cuda" # cuda不可用,会自动切换cpu
# ,trust_remote_code=True
)
@app.route('/asr', methods=['POST'])
def recognize():
if 'audio' not in request.files:
return R.fail("请求参数不能为空:audio")
audio_file = request.files['audio']
if audio_file.filename == '':
return R.fail("文件不能为空")
filename = str(np.random.randint(10 ** 7, 10 ** 8)) + audio_file.filename
save_path = f"/tmp/{filename}"
audio_file.save(save_path)
try:
result = model.generate(input=save_path)
os.remove(save_path)
return R.ok(result, "请求成功")
except Exception as e:
if os.path.exists(save_path):
os.remove(save_path)
return R.failCode(500, "系统异常:" + str(e.args))
@app.route('/health', methods=['GET'])
def health_check():
return R.ok(None, "success")
if __name__ == '__main__':
if not os.path.exists(MODEL_DIR):
os.makedirs(MODEL_DIR)
print(
f"warm: model {MODEL_DIR} not find,Created. Please ensure that the model has been downloaded to this directory.")
app.run(host='0.0.0.0', port=5000, debug=False)
启动
python voice_server.py
4、测试
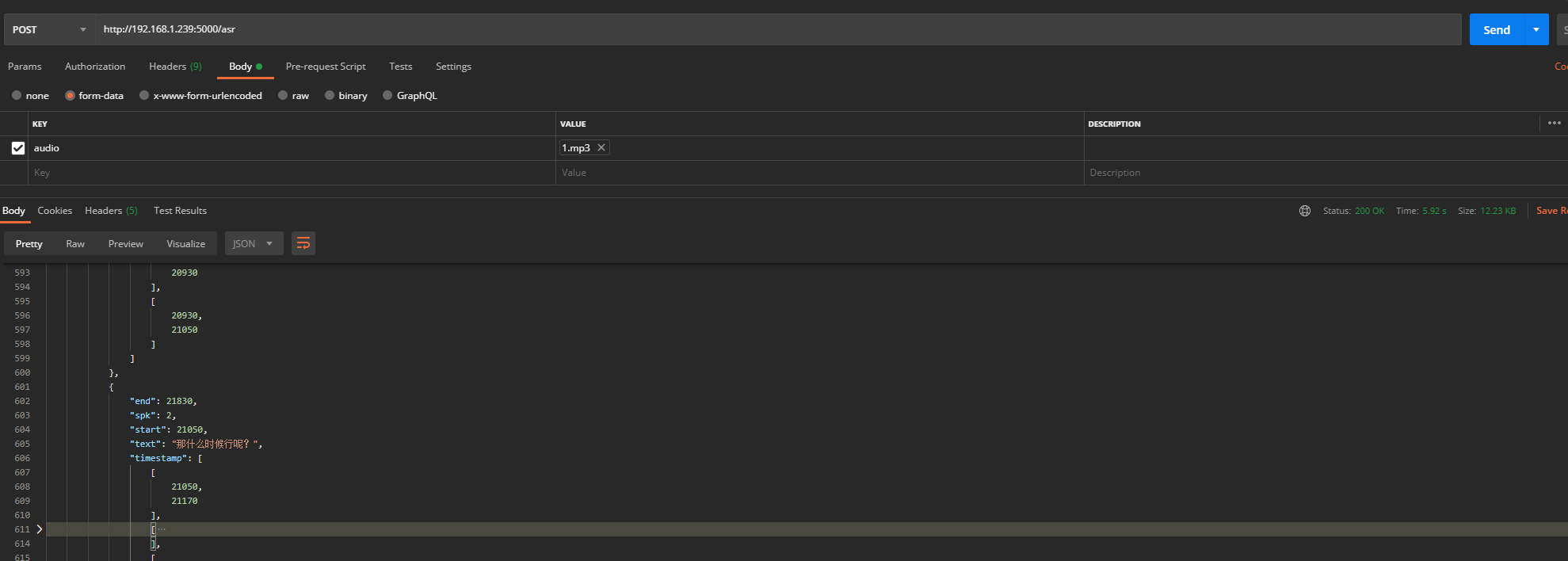
5、使用Waitress部署
安装Waitress,这里省略,查看另一篇
创建文件:Waitress_server_voice.py
from waitress import serve
from voice_server import app
import os
from utils import LogFactory
def main():
"""主启动函数"""
try:
# 获取环境变量配置,提供灵活性
host = os.getenv('SERVER_HOST', '0.0.0.0')
port = int(os.getenv('SERVER_PORT', '5002'))
# 生产环境推荐配置
server_config = {
'host': host,
'port': port,
'threads': int(os.getenv('WAITRESS_THREADS', '4')), # 线程数,根据CPU核心数调整
'channel_timeout': int(os.getenv('WAITRESS_TIMEOUT', '600')), # 超时时间 10分钟
'max_request_body_size': int(os.getenv('MAX_BODY_SIZE', '1073741824')), # 1GB 最大请求体
'connection_limit': int(os.getenv('CONNECTION_LIMIT', '1000')), # 连接限制
'asyncore_loop_timeout': 1, # 异步循环超时
'send_bytes': 102400, # 发送缓冲区大小 100M
'ident': 'FunASR Voice Server' # 服务器标识
}
LogFactory.log.info(f"启动 FunASR 语音服务器...")
LogFactory.log.info(f"服务地址: {host}:{port}")
LogFactory.log.info(f"配置参数: {server_config}")
# 启动服务器
serve(app, **server_config)
except KeyboardInterrupt:
LogFactory.log.info("服务器被用户中断")
except Exception as e:
LogFactory.log.error(f"服务器启动失败: {e}")
raise
if __name__ == '__main__':
main()
直接运行即可
python Waitress_server_voice.py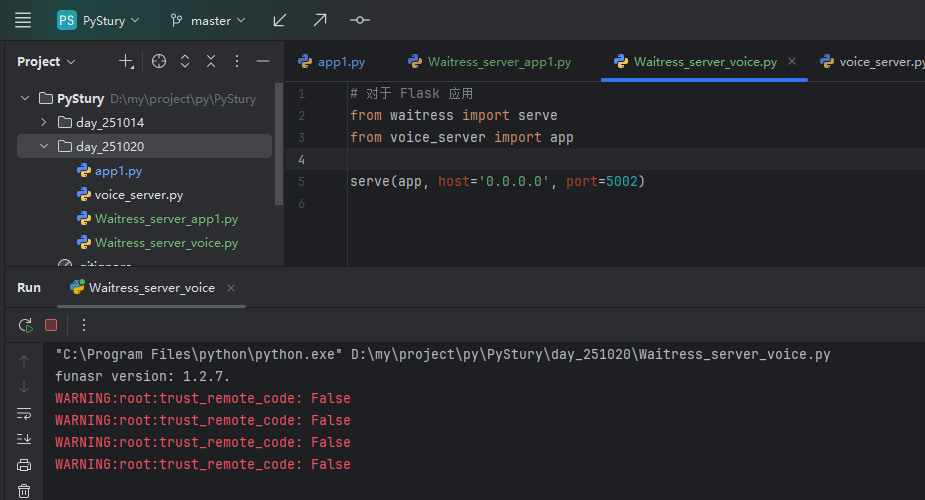
6、测试GPU
6.1、查看环境
6.1.1 查看显卡
nvidia-smi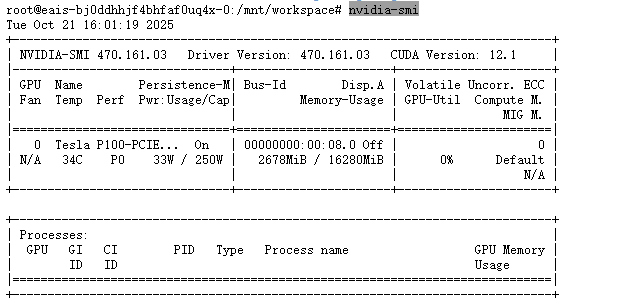
nvidia-smi -L
6.1.2 查看cuda版本
nvcc --version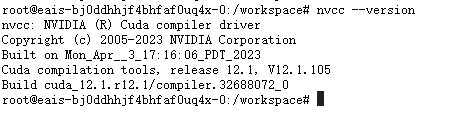
6.1.3 查看pytorch
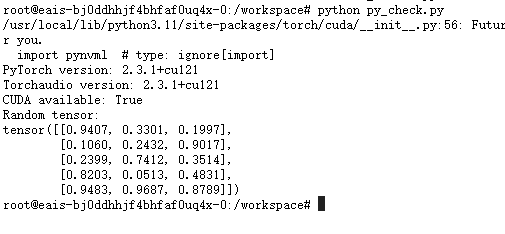
6.1.4 查看python环境
flask

waitress
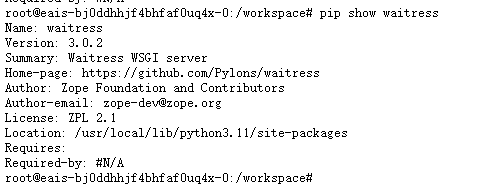
python
pip

6.1.5 查看FunAsr

6.1.6 查看FFmpeg

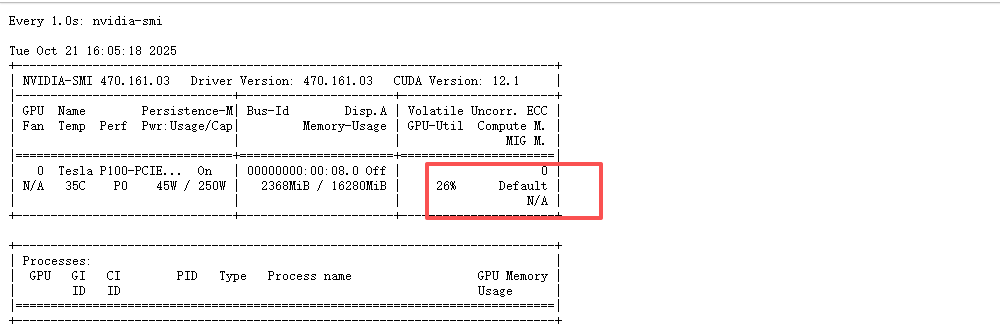
6.2、动态监控显卡,1s钟刷新一次
watch -n 1 nvidia-smi
6.3、修改voice_server.py 的device="cuda"
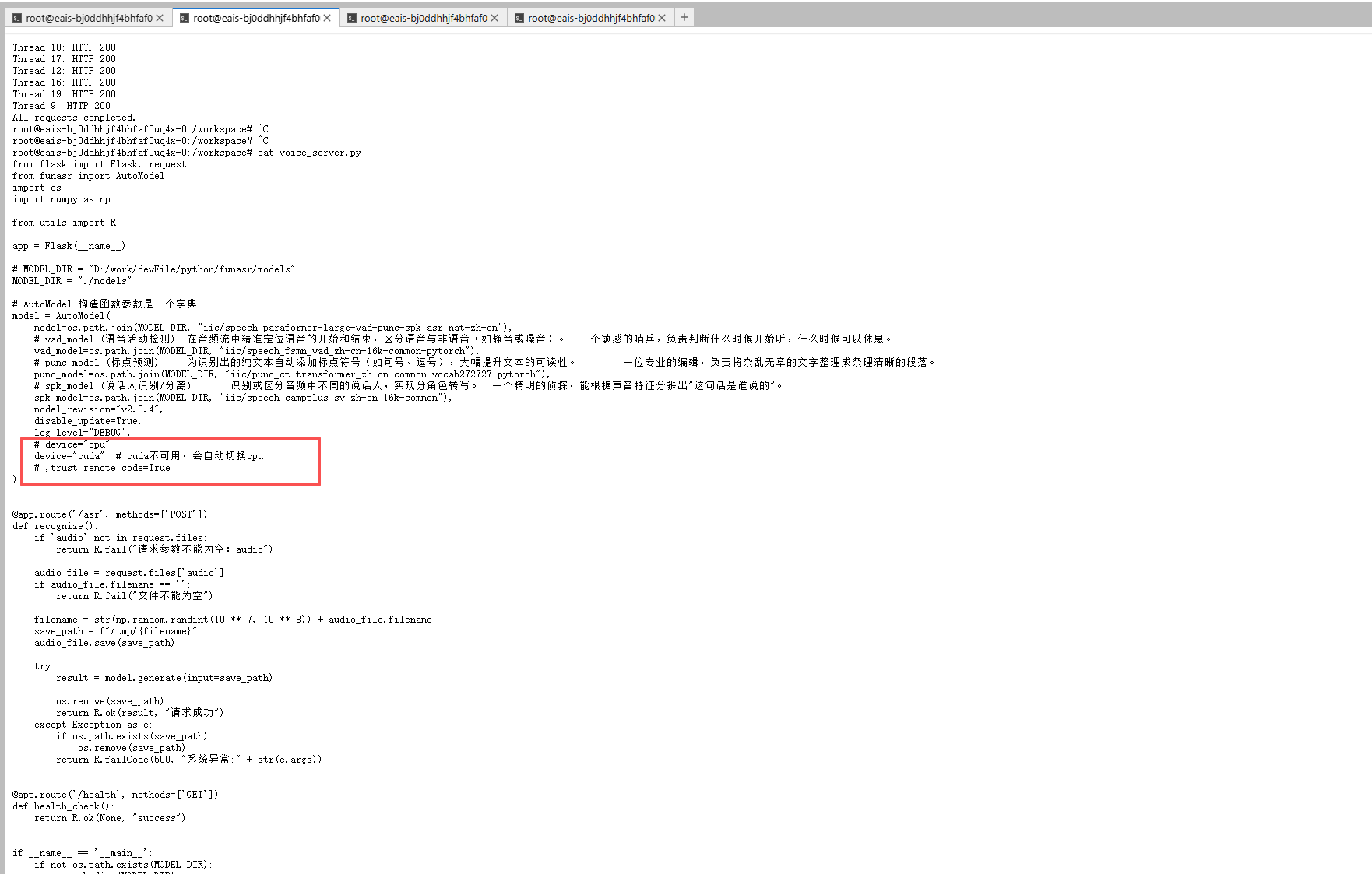
6.4、启动,或者使用waitress启动
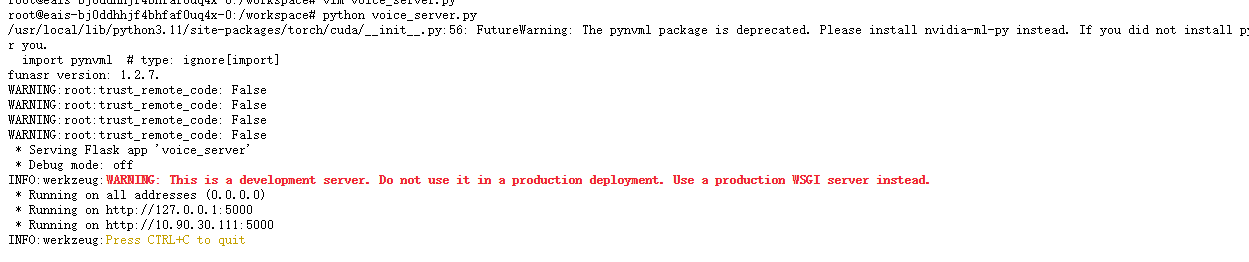
6.5、测试
1、创建并发20个线程,执行
start.sh
#!/bin/bash
URL="http://10.90.30.111:5000/asr"
THREADS=20
seq 1 $THREADS | xargs -P $THREADS -I {} \
curl -X POST "$URL" -F "audio=@1.mp3" -s -o /dev/null -w "Thread {}: HTTP %{http_code}\n"
echo "All requests completed."执行
sh start.sh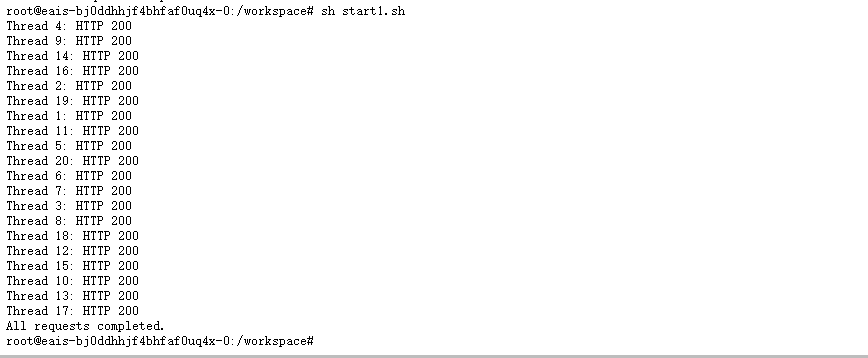
查看显卡负载